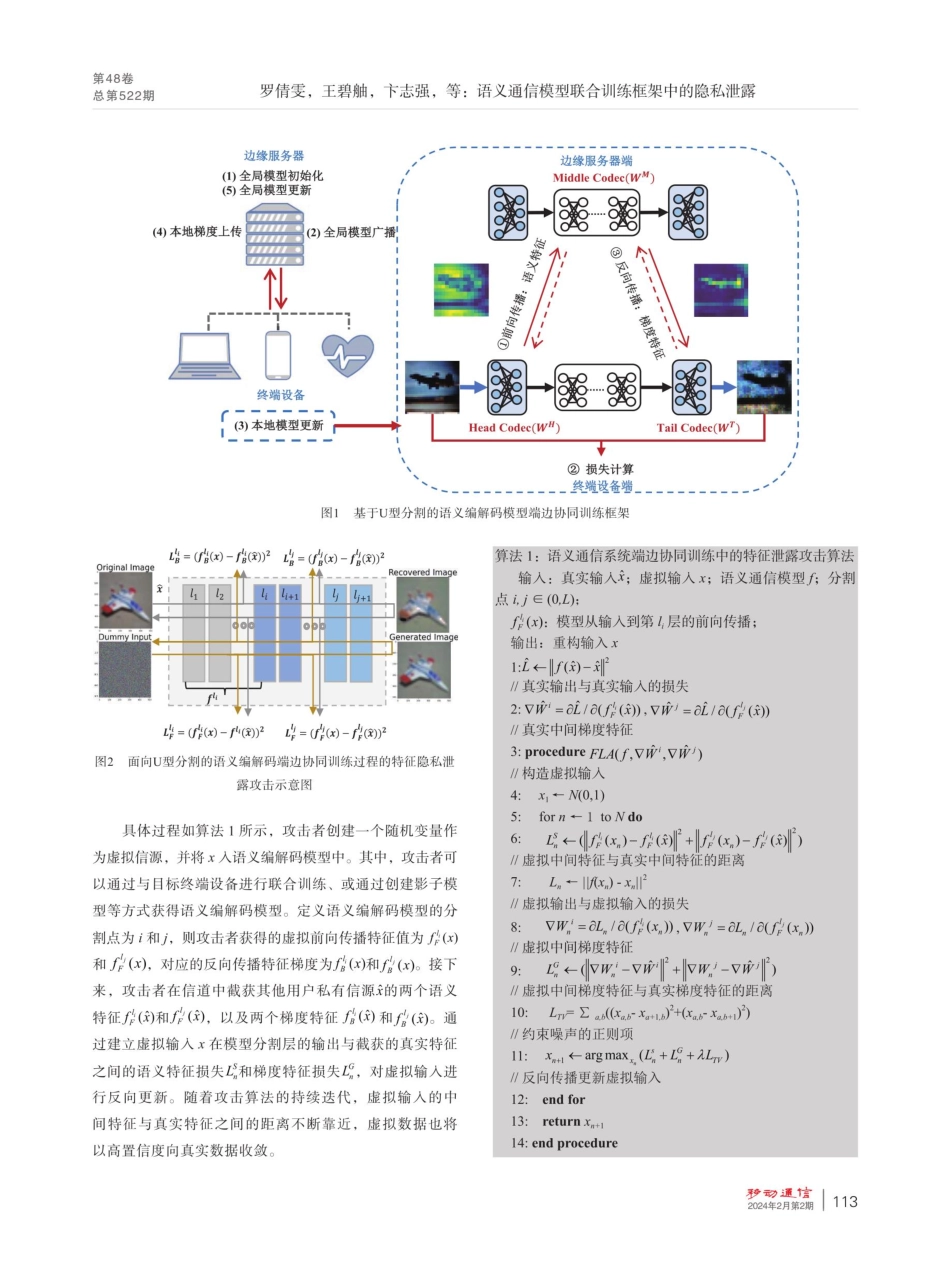
第48卷总第522期语义通信模型联合训练框架中的隐私泄露罗倩雯,王碧触,卞志强,许晓东,韩书君,张静璇(北京邮电大学网络与交换技术国家重点实验室,北京100876)【摘要】为了同时保障端边协同训练语义编解码模型过程中的模型训练效率与数据隐私保护,基于U型分割的语义编解码模型端边协同训练框架是一种可行的方法。然而,端边之间交互的中间特征值与特征梯度仍然可能会泄露终端设备的数据隐私。基于U型分割的语义编解码模型端边协同训练框架可以在一定程度上解决端边协同训练语义编解码模型过程中模型训练效率与数据隐私保护之间的矛盾。然而,该框架下端边之间的交互过程仍然可能泄露终端设备的数据隐私。针对这一问题,提出了一种面向U型分割语义编解码模型协同训练过程的特征泄露攻击算法,通过分析训练过程中终端设备与边缘服务器之间交互的中间特征值和特征梯度,对终端的私有隐私数据进行重构。仿真结果表明,当使用单回合中间特征值对终端数据进行推断时,语义编解码模型使用浅层分割点或模型训练轮次较多时,中间特征值会包含更多的数据语义信息。此外,当攻击者增加本地攻击迭代次数,并选取多回合中间特征值和特征梯度对终端数据进行推断时,重构的终端数据与真实数据的图像结构相似度可以从0.2759提升到0.4017。【关键词】语义通信;端边协同训练;数据重构;隐私泄露;模型分割doi:10.3969/j.issn.1006-1010.20231225-0004中图分类号:TN929.5文献标志码:A文章编号:1006-1010(2024)02-0111-06引用格式:罗倩雯,王碧触,下志强,等.语义通信模型联合训练框架中的隐私泄露[].移动通信,2024,48(2):111-116.LUOQianwen,WANGBizhu,BIANZhiqiang,etal.PrivacyLeakageinJointTrainingFrameworkforSemanticCommunicationModels[J.MobileCommunications,2024,48(2):111-116.PrivacyLeakageinJointTrainingFrameworkforSemanticLUOQianwen,WANGBizhu,BIANZhiqiang,XUXiaodong,HANShujun,ZHANGJingxuan(StateKeyLaboratoryofNetworkingandSwitchingTechnology,BejingUniversityofPostsandTelecommunications,Beijing100876,China)[Abstract]segmentationisafeasibleapproach.However,theintermediatefeaturevaluesandfeaturegradientsinteractedbetweentheendedgesmaystillleakthedataprivacyoftheenddevices.TheU-shapedsegmentation-basedend-edgecollaborativetrainingframeworkcanresolvetheconflictbetweenmodeltrainingefficiencyanddat...