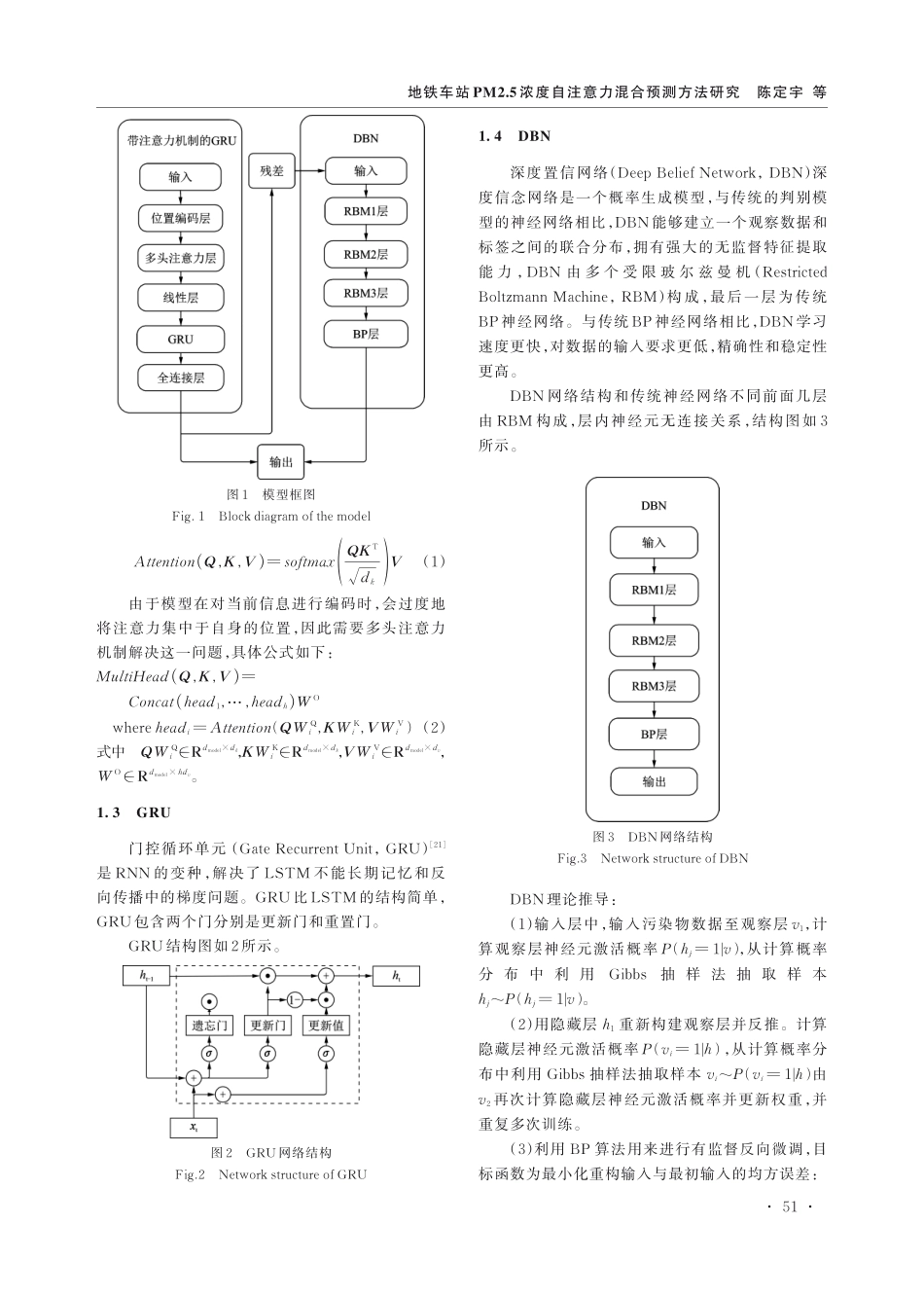
2024.1,4(1)|智能交通与数字化地铁车站PM2.5浓度自注意力混合预测方法研究陈定宇1,高国飞1,袁泉2(1.北京城建设计发展集团股份有限公司,北京,100037;2.广州地铁设计研究院有限公司,广东广州510010)摘要:建立可靠的空气质量预测模型对经济发展和污染治理至关重要,解决PM2.5浓度的预测问题成为当务之急。本文提出了一种基于自注意力机制的混合预测方法,旨在提高PM2.5浓度的预测精度。使用自注意力机制来捕捉序列中的关键信息;用GRU对序列进行预测;使用DBN对误差序列进行校正,以提高预测的准确性和稳定性,形成了最终的预测序列。为了验证模型的性能,以我国四个地铁车站的室外PM2.5数据为例进行数据处理和预测。结果表明,预测模型在准确性和稳定性方面优于其他参照模型,为决策者提供了科学依据,以更好地治理大气污染问题。关键词:PM2.5;预测;自注意力机制;门控循环单元(GRU);深度信念网络(DBN)Researchonself‑attentionhybridpredictionmethodforPM2.5concentrationinsubwaystationsCHENDingyu1,GAOGuofei1,YUANQuan2(1.BeijingUrbanConstructionDesign&DevelopmentGroupCo.,Limited,Beijing100037,China;2.GuangzhouMetroDesign&ResearchInstituteCo.,Ltd.,Guangzhou510010,China)Abstract:Itisofgreatsignificancetoestablishareliableairqualitypredictionmodelforeconomicde⁃velopmentandpollutioncontrol.SincePM2.5isthemainpollutantinmostpartsofChina,ithasbe⁃comeatopprioritytosolvetheproblemofpredictingPM2.5concentration.Inthispaper,weproposeanerrorcorrectionmodelbasedontheself-attentionmechanismtoimprovethepredictionaccuracyofPM2.5concentration.Thispaperusesaself-attentionmechanismtocapturekeyinformationinthese⁃quence.TheGRUisusedtopredictthesequence.TheDBNisusedtocorrecttheerrorseriestoim⁃provetheaccuracyandstabilityoftheprediction,andthefinalpredictionsequenceisformed.Inordertoverifytheperformanceofthemodel,thispapertakestheoutdoorPM2.5datafromBeijing,Tian⁃jin,Shanghai,andGuangzhouinChinaformetrostationsasexamplesfordataprocessingandpredic⁃tion.Theresultsshowthatthepredictionmodelinthispaperissuperiortootherreferencemodelsintermsofaccuracyandstability,andprovidesascientificbasisfordecision-makerstobettercont...