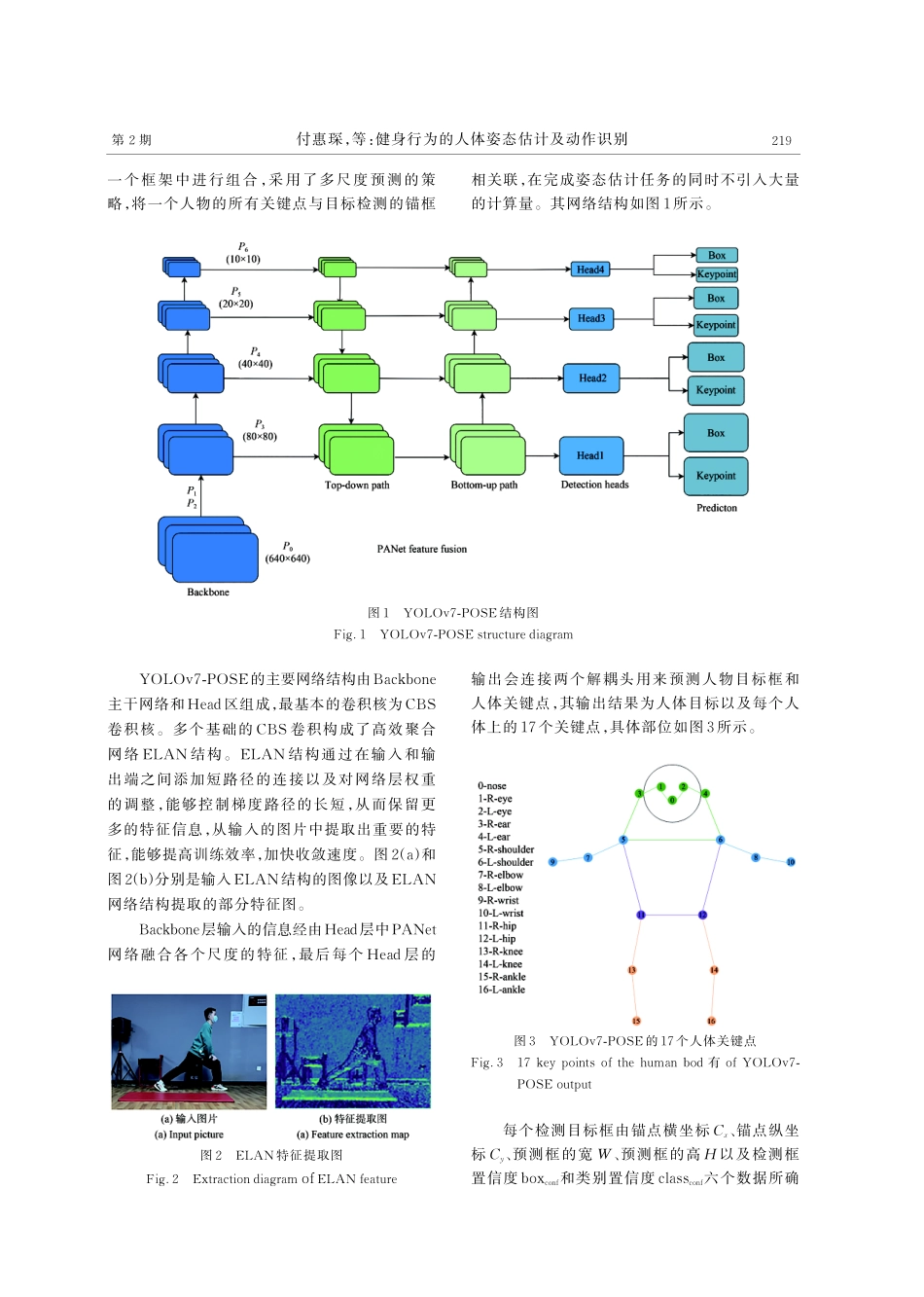
第39卷第2期2024年2月Vol.39No.2Feb.2024液晶与显示ChineseJournalofLiquidCrystalsandDisplays健身行为的人体姿态估计及动作识别付惠琛1,2,高军伟1,2*,车鲁阳1,2(1.青岛大学自动化学院,山东青岛266071;2.山东省工业控制技术重点实验室,山东青岛266071)摘要:人体姿态估计和动作识别在安防、医疗和运动等领域有着重要的应用价值。为了解决不同背景及角度下各类运动动作的人体姿态估计和动作识别问题,本文提出了一种改进的YOLOv7-POSE算法,并自行拍摄制作各种拍摄角度的数据集进行训练。此算法以YOLOv7为基础,对原始网络模型添加了分类的功能,在Backbone主干网络中引入CA卷积注意力机制,提升了网络在对人体骨骼关节点和动作的分类的重要特征的识别能力。用HorNet网络结构代替原模型的CBS卷积核,提高了模型的人体关键点检测精度和动作分类的准确度。将Head层的空间金字塔池化结构替换为空洞空间金字塔池化结构,提升了检测精度并且加快了模型收敛。将目标检测框的回归函数由CIOU替换为EIOU,提高了坐标回归的精度。设计了两组对照实验,实验结果证明,改进后的YOLOv7-POSE在验证集上的mAP为95.7%,相比于原始YOLOv7算法提高了4%,各类运动动作识别准确率显著上升,在实际推理中的关键点错检、漏检等情况明显减少,关键点位置估计误差明显降低。关键词:图像处理;关键点检测;姿态估计;注意力机制;空洞空间金字塔池化中图分类号:TP391.4文献标识码:Adoi:10.37188/CJLCD.2023-0127HumanpostureestimationandmovementrecognitioninfitnessbehaviorFUHuichen1,2,GAOJunwei1,2*,CHELuyang1,2(1.SchoolofAutomation,QingdaoUniversity,Qingdao266071,China;2.ShandongKeyLaboratoryofIndustrialControlTechnology,Qingdao266071,China)Abstract:Humanposeestimationandmotionrecognitionhaveimportantapplicationvalueinthefieldsofsecurity,medicaltreatmentandsports.Inordertosolvetheproblemofhumanposeestimationandmotionrecognitionofvariousmovementsundercomplexbackground,animprovedYOLOv7-POSEalgorithmisproposed,anddatasetsofvariousshootinganglesaremadebyoneselffortraining.BasedonYOLOv7,thisalgorithmaddsclassificationfunctiontooriginalnetworkmodel.CAconvolutionalattentionmechanismisintroducedintoBackbonenetwork,whichimprovesrecognitionabilityofimportantfeaturesintheclassif...