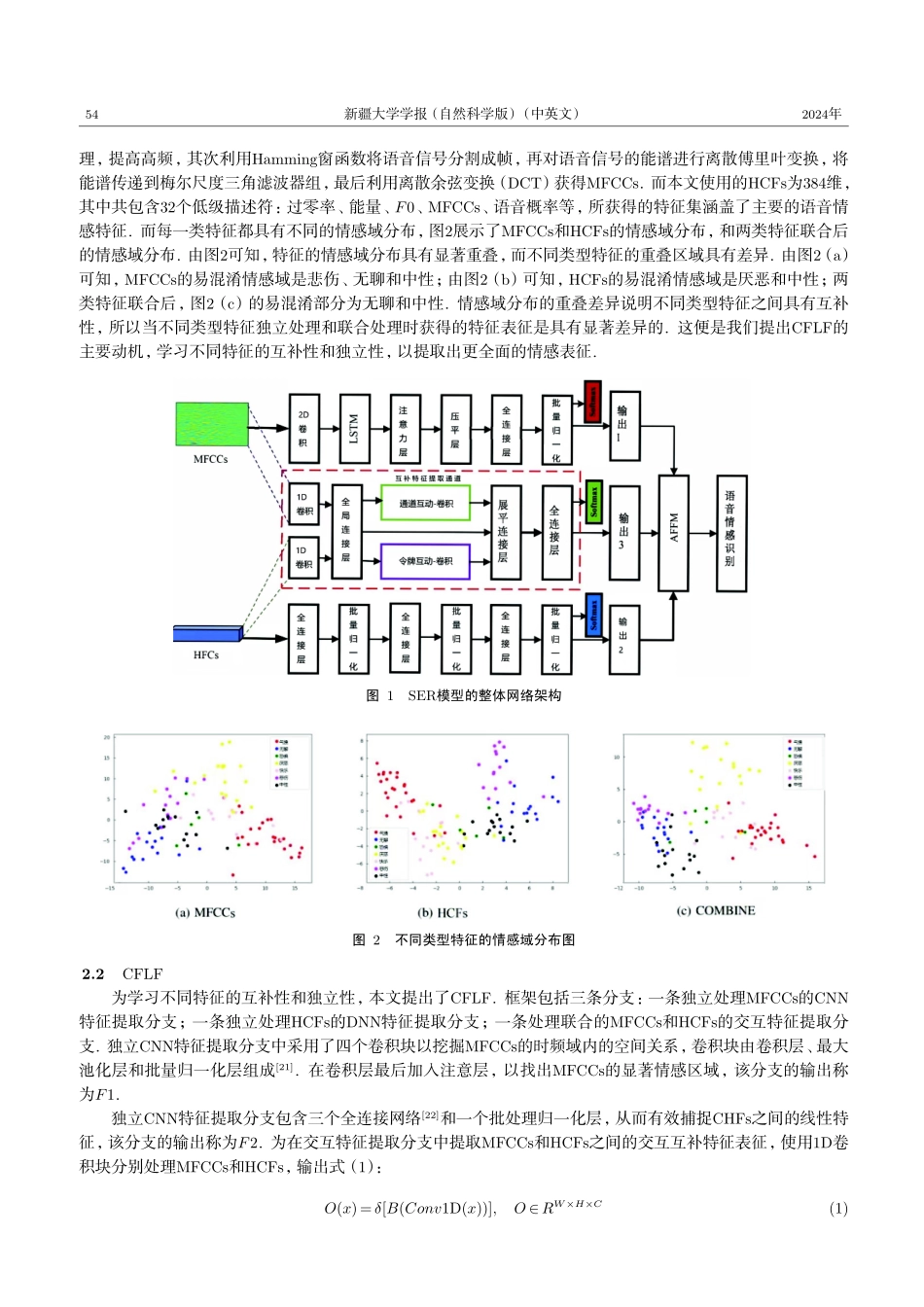
第41卷第1期2024年1月新疆大学学报(自然科学版)(中英文)JournalofXinjiangUniversity(NaturalScienceEditioninChineseandEnglish)Vol.41,No.1Jan.,2024具有互补特征学习框架和注意力特征融合模块的语音情感识别模型∗黄佩瑶1,程慧慧2,唐小煜1,2†(1.华南师范大学工学部电子与信息工程学院,广东佛山528225;2.华南师范大学物理学院,广东广州510006)摘要:针对深度学习的特征提取方法无法全面提取语音中的情感特征,也无法有效地融合这些特征的问题,提出了一种集成互补特征学习框架和注意力特征融合模块的语音情感识别模型.该互补特征学习框架包含两条独立的表征提取分支和一条交互互补表征提取分支,能够全面覆盖情感特征的独立性表征和互补性表征.为了进一步优化模型性能,引入注意力特征融合模块,该模块能够根据不同表征对情感分类的贡献程度分配合适的权重,使模型能最大程度地关注对情感识别最有助的特征.基于两个公开情感数据库(Emo-DB和IEMOCAP)的仿真实验结果,验证了所提模型的鲁棒性和有效性.关键词:语音情感识别;深度神经网络;情感特征表征;特征提取器;特征融合;注意力机制;人工智能DOI:10.13568/j.cnki.651094.651316.2023.07.05.0002中图分类号:TN912;TP391文献标识码:A文章编号:2096-7675(2024)01-0052-07引文格式:黄佩瑶,程慧慧,唐小煜.具有互补特征学习框架和注意力特征融合模块的语音情感识别模型[J].新疆大学学报(自然科学版)(中英文),2024,41(1):52-58.英文引文格式:HUANGPeiyao,CHENGHuihui,TANGXiaoyu.Speechemotionrecognitionwithcomplementaryfeaturelearningframeworkandattentionalfeaturefusionmodule[J].JournalofXinjiangUniversity(NaturalScienceEditioninChineseandEnglish),2024,41(1):52-58.SpeechEmotionRecognitionwithComplementaryFeatureLearningFrameworkandAttentionalFeatureFusionModuleHUANGPeiyao1,CHENGHuihui2,TANGXiaoyu1,2(1.SchoolofElectronicsandInformationEngineering,FacultyofEngineering,SouthChinaNormalUniversity,FoshanGuangdong528225,China;2.SchoolofPhysics,SouthChinaNormalUniversity,GuangzhouGuangdong510006,China)Abstract:Addressingthelimitationsofdeeplearningfeatureextractionmethods,whichfailtocomprehensivelyextractandeffectivelyintegrateemotionalfeaturesfromspeech,thispaperproposesanovelspeechemotionreco...