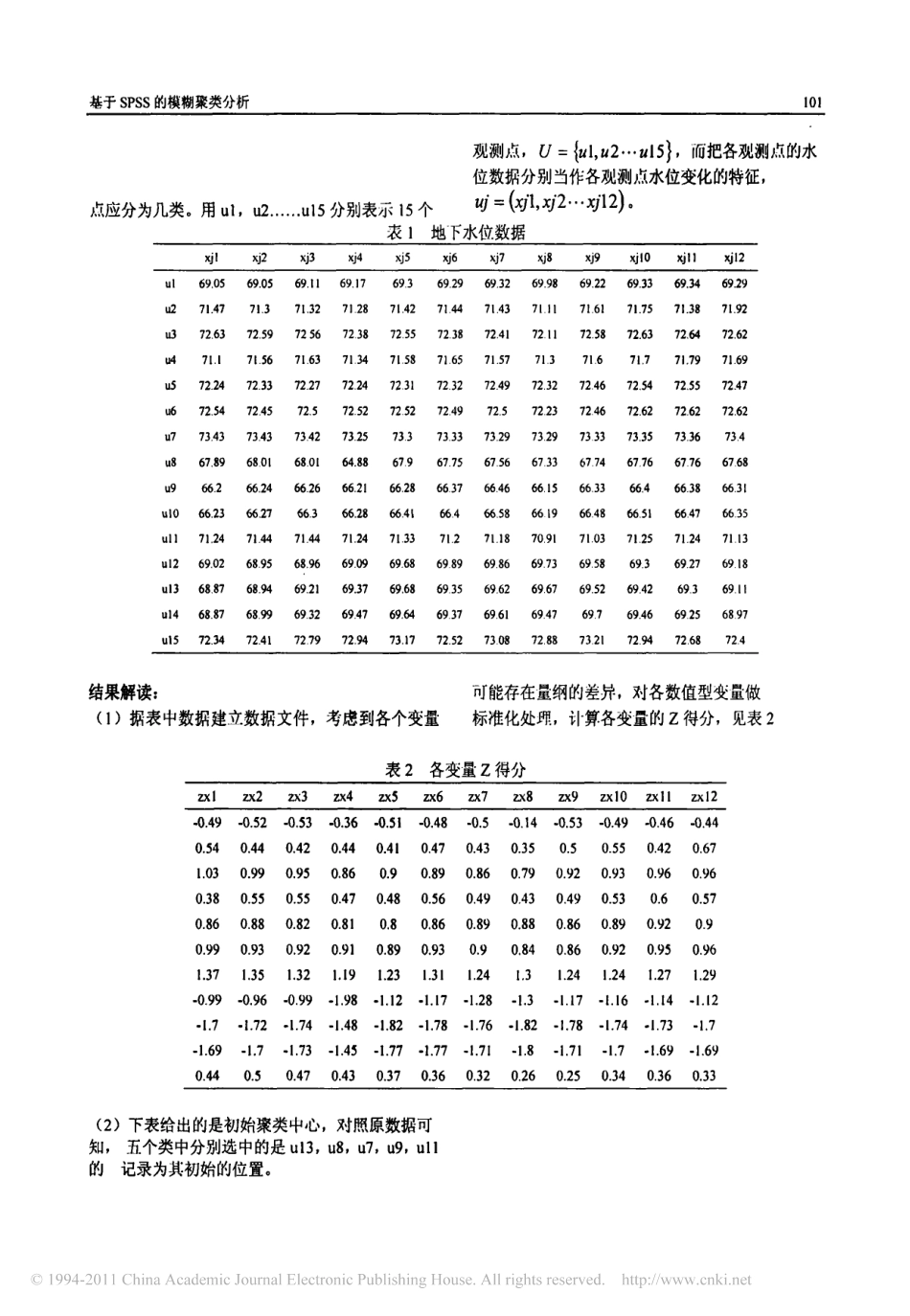
基于����的模糊聚类分析张春月,李晓奇东北大学理学院,数学系,!级硕士研究生,辽宁,沈阳,∀#∃东北大学秦皇岛分校,信息与计算科学系,河北,秦皇岛,%%∃&!∋()∗+,(−∗.−/0#%12,34,5676)3#8∃093(−2,34摘要:本文运用����软件分析方法,通过;<4/)∗9算法和=>?算法,结合实例对数据进行聚类,并对聚类结果进行了对比和分析。&2#计算过程关键词:模糊聚类,9�99,;<4/)∗9,=,?#引言聚类就是按照一定的要求和规律对事物进行区分和分类的过程,将数据点的集合分成若干类或簇,使得每个簇中的数据点之间最大程度地相似,而不同簇中的数据点最大程度地不同2增强数据集的可理解性,发现数据集中数据之间有效的内在结构和联系2在这一过程中没有任何关于分类的先验知识,没有教师指导,仅靠事物间的相似性作为类属划分的准则,因此属于无监督分类的范畴2模糊聚类分析是按一定要求和规律对模糊性问题加以处理。聚类的结论并不纯粹地表示对象绝对地属于或不属于某一类,而是以白化的特征值表征了对象在什么程度上相对地属于某一类。自∋/≅/(教授ΑΒΧ年创立模糊集理论以来,利用模糊集理论进行模式分类取得了很多有意义的成果2人们一直希望能够找到一种又快又好的聚类方法,而����强大的软件功能,免去?)ΔΑ)Ε、=3ΦΔΦ)∗语言等编程的冗余,更加方便、有效2。&两种聚类算法ΓΑΗ一首先需要指定聚成多少类,Γ比如;类Η。计算这;个类的初始类中心,确定中心点。Γ&Η按照距;个类中心点距离最短原则,把所有样本分派到各中心点所在的类中,形成一个新的;类,完成一步迭代过程。Γ1Η9�99计算每个类中各个变量的变量值均值,并以均值点作为新的类中心点。Γ∃Η重复第Γ1Η,Γ∃Η步直到达到指定的迭代次数或终止迭代的判断要求为止。&2&应用参数ΓΑΗ欧氏距离:。/:,Ιϑ、Κ艺Γ7,一,‘Η&其中;表示每个样本有;个变量,戈表示第一个样本在第6个变量上的取值Λ戈表示第二个样本在第6个变最上的取值。Γ&Η�/)Φ93∗相关系数=,?算法是一种基于划分的聚类算法,它是对于普通;<4/)∗9算法的改进。普通卜4/)∗9算法对于数据的划分是硬性的,而=>?则是一种柔性的模糊划分。聚类分析算法的基木思想是首先进行初始化聚类,然后通过反复迭代运算不断形成新的分类后计算新的目标函数,使目标函数达到最小,当两次目标函数变化差异足够小时停止迭代。艺Γ7Μ一刃》,一动ϑ一一&已一——<—<—<—一一艺Γ7‘一对艺Γ7,一扮;二5;一ΑΓ1Η相似矩阵正常情况下取值范围为:Ν‘几‘#,当几...