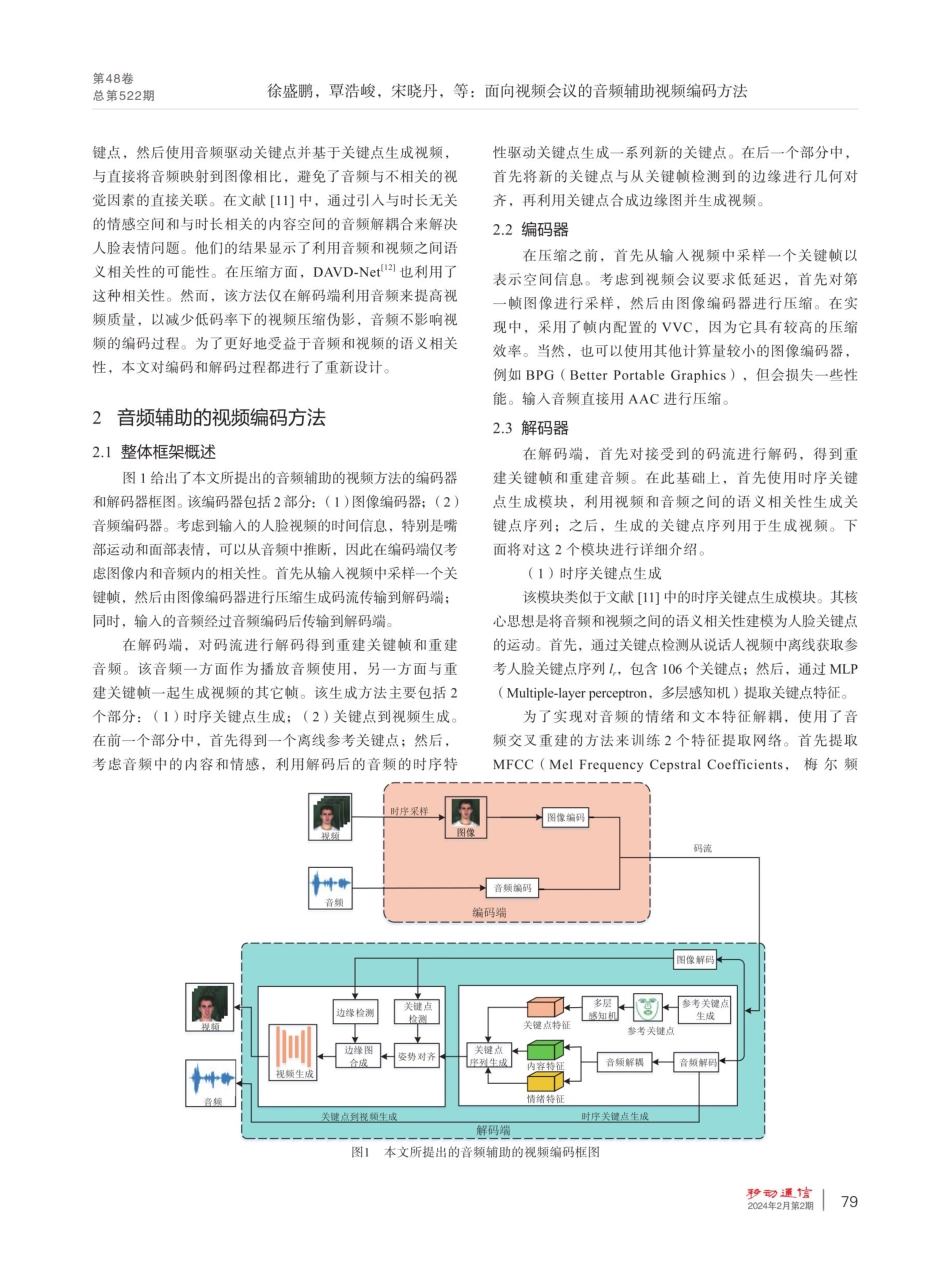
第48卷总第522期面向视频会议的音频辅助视频编码方法徐盛鹏",覃浩峻",宋晓丹1.2*,左旭光”,高大化",谢雪梅,石光明!(1.西安电子科技大学,陕西西安710071;2.西安电子科技大学广州研究院,广东广州510555;3.铭微电子(上海)有限公司,上海200120)【摘要】目前视频会议所包含的视频和音频通常是使用传统的编码标准分别进行压缩。然而从语义层面看,音频和视频存在强相关性,都是对与会者所要表述内容的表征。因此,对两者分开编码是次优的。针对此问题,提出了一种音频辅助的视频编码框架。该框架中视频只传输少量的关键顿以提供必要的纹理参考,利用从重建音频中推理得到时序信息和关键顿来重建其余顿。实验结果表明,与通用视频编码方法相比,该框架在指标DISTS下取得了-89.81%的BD-rate结果。【关键词】多模态信源编码;音频辅助视频编码;视频会议;低码率;语义保真度doi:10.3969/j.issn.1006-1010.20231219-0004文献标志码:A文章编号:1006-1010(2024)02-0077-06引用格式:徐盛鹏,覃浩峻,宋晓丹,等面向视频会议的音频辅助视频编码方法[].移动通信,2024,48(2):77-82.XUShengpeng,QINHaojun,SONGXiaodan,etal.AnAudio-aidedVideoCompressionMethodforVideoConferencing[J.MobileCommunications,2024,48(2):77-82.AnAudio-aidedVideoCompressionMethodforVideoConferencingXUShengpeng',QINHaojun',SONGXiaodan'2,ZUOXuguang,GAODahua',XIEXuemei',SHIGuangming[Abstract]Duringvideocommunications,bandwidthisoftenlimitedduetonetworkfluctuationsorharshenvironments,andtheuserexperiencereliesheavilyonthecompressionefficiencyofvideoandaudio.Althoughvideocompressionefficiencyhasbeensignificantlyimproved,thevideoreconstructionstillsuffersfromseveredistortion,blurringorblockartifactsatlowbitrate.Thevideoandaudioinvideoconferencingareusuallycompressedseparatelyusingtraditionalcodingstandards.However,fromtheviewofsemantics,audioandvideoarestronglycorrelatedduetothesamespeakers'intendingmeaning.Thus,theseparatecompressionmethodsaresub-optimal.Toaddresstheseproblems,inspiredbytheworkonaudio-driventalkingfacegeneration,anaudio-aidedvideocodingframeworkisproposed.Theideaisthatthetemporalinformationwithinthevideocanbeinferredfromtheaudioandthuscanberemovedfromtransmission...