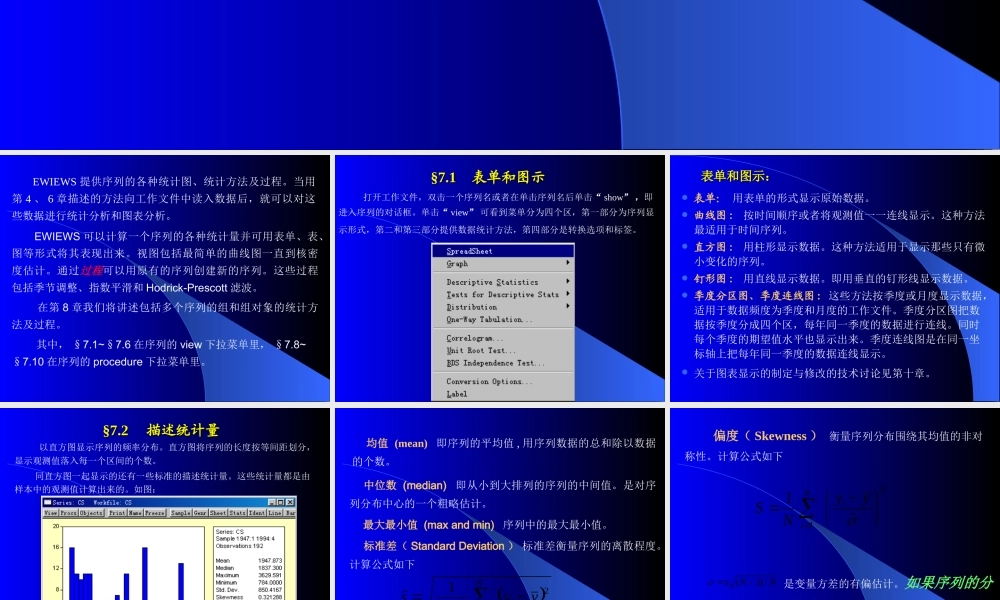
第七章序列第七章序列EWIEWS提供序列的各种统计图、统计方法及过程。当用第4、6章描述的方法向工作文件中读入数据后,就可以对这些数据进行统计分析和图表分析。EWIEWS可以计算一个序列的各种统计量并可用表单、表、图等形式将其表现出来。视图包括最简单的曲线图一直到核密度估计。通过过程可以用原有的序列创建新的序列。这些过程包括季节调整、指数平滑和Hodrick-Prescott滤波。在第8章我们将讲述包括多个序列的组和组对象的统计方法及过程。其中,§7.1~§7.6在序列的view下拉菜单里,§7.8~§7.10在序列的procedure下拉菜单里。§7.1§7.1表单和图示表单和图示打开工作文件,双击一个序列名或者在单击序列名后单击“show”,即进入序列的对话框。单击“view”可看到菜单分为四个区,第一部分为序列显示形式,第二和第三部分提供数据统计方法,第四部分是转换选项和标签。表单和图示:表单和图示:表单:用表单的形式显示原始数据。曲线图:按时间顺序或者将观测值一一连线显示。这种方法最适用于时间序列。直方图:用柱形显示数据。这种方法适用于显示那些只有微小变化的序列。钉形图:用直线显示数据。即用垂直的钉形线显示数据。季度分区图、季度连线图:这些方法按季度或月度显示数据,适用于数据频度为季度和月度的工作文件。季度分区图把数据按季度分成四个区,每年同一季度的数据进行连线。同时每个季度的期望值水平也显示出来。季度连线图是在同一坐标轴上把每年同一季度的数据连线显示。关于图表显示的制定与修改的技术讨论见第十章。§7.2§7.2描述统计量描述统计量以直方图显示序列的频率分布。直方图将序列的长度按等间距划分,显示观测值落入每一个区间的个数。同直方图一起显示的还有一些标准的描述统计量。这些统计量都是由样本中的观测值计算出来的。如图:均值(mean)即序列的平均值,用序列数据的总和除以数据的个数。2111ˆyyNsiNi中位数(median)即从小到大排列的序列的中间值。是对序列分布中心的一个粗略估计。最大最小值(maxandmin)序列中的最大最小值。标准差(StandardDeviation)标准差衡量序列的离散程度。计算公式如下N是样本中观测值的个数,是样本均值。y偏度(Skewness)衡量序列分布围绕其均值的非对称性。计算公式如下31ˆ1yyNSiNi是变量方差的有偏估计。如果序列的分布是对称的,S值为0;正的S值意味着序列分布有长的右拖尾,负的S值意味着序列分布有长的左拖尾NN...