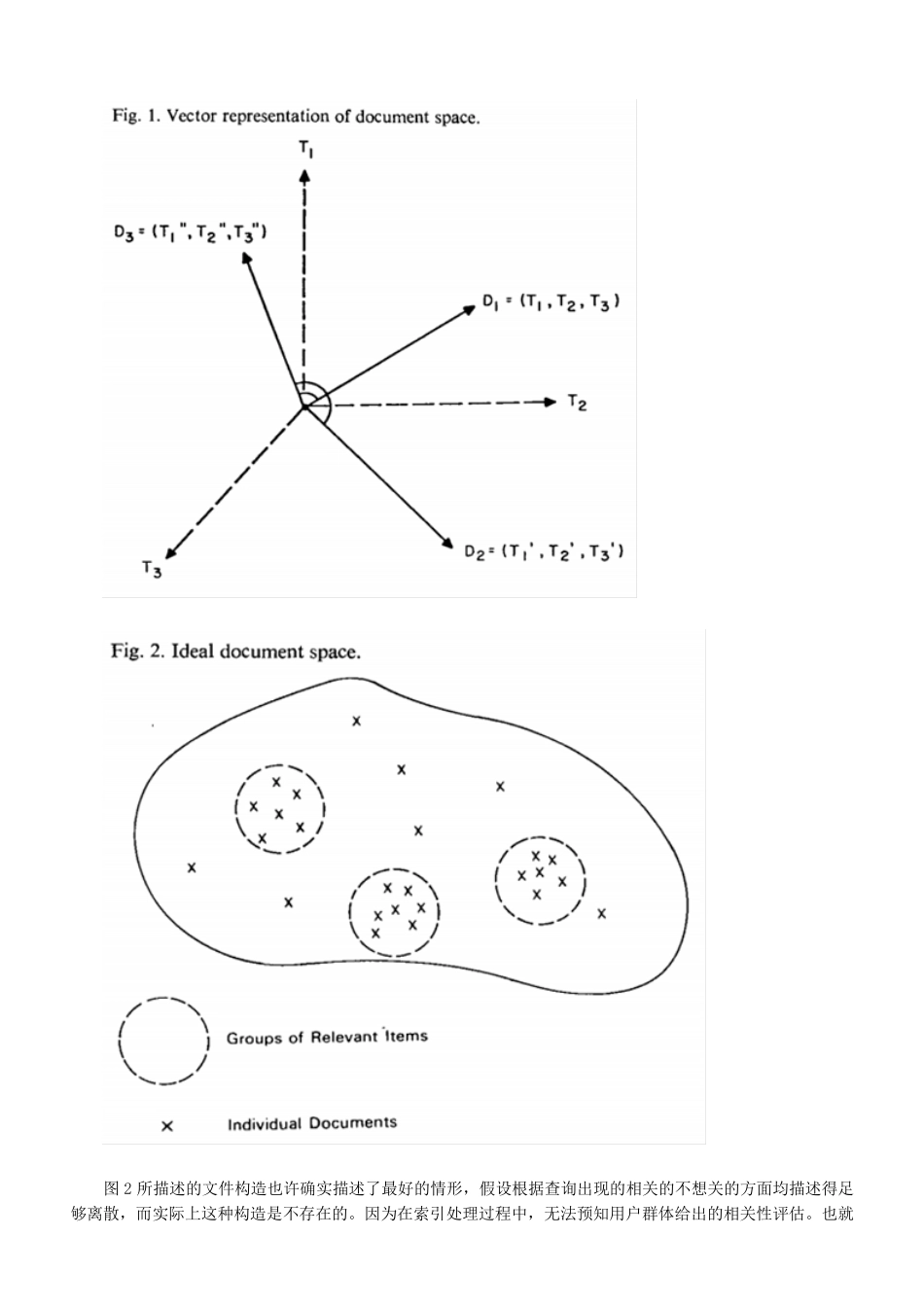
自动索引的矢量空间模型综述刘博宁(兰州大学,730001)摘要:在文件检索,或者是存储的实体文件之间比较以及与输入模式(搜索请求)比较的情形下,最好的索引(特征)空间是存储实体之间相距越远越好;在这种情形下,一个索引系统的键值可以用对象空间的密度函数来确定;特别地,检索表现可能与空间密度反相关。基于空间密度的一种计算方法曾经常常用于为文件集合确定合适的索引值。典型的估计结果表明了这个模型的有效性。Abstract:Inthecaseofrelativelywellcomparedwiththeinputmodebetweenentitiesfileretrievalorstorage,thebestindex(feature)spaceisthedistancebetweenthefartherthebetterstorageentity;inthiscase,anindexsystemdensityfunctionkeyscanbeusedtodeterminetheobjectspace;inparticular,thesearchmaybeinverselycorrelatedwiththeperformancespacedensity.Acalculationmethodbasedonthespatialdensityhasbeenoftenusedtodeterminetheappropriateindexvaluesforthecollectionoffiles.Typicalestimationresultsshowtheeffectivenessofthismodel.关键词:自动信息检索;自动索引;文本分析;文件空间1文件空间构造设想一个文件空间由文件Di构成,每一个文件空间由若干个索引项Tj识别;每一个索引项可能会根据文件的重要程度加权,或者将权值减至0或11。在t维相异的索引项出现时,三维的例子或许可以变为t维的。在这种情况下,每个文件Di表示为一个t维矢量Di=(di1,di2,....dit),dij表示的是第j个索引项的权值。给出两个文件的索引矢量,计算它们之间的相似系数S(Dj,Di)是可能的。S(Dj,Di)反应了对应索引项以及其系数的相似度。这个相似度的大小可能就是这两个矢量的点积,另外一个可能就是相应的两个矢量对之间角度的反函数。当索引项分配了两个完全一样的矢量时,这两个矢量之间的夹角就是0度,产生一个最大的相似度。对于每一个文件标示,并不是在坐标系中用从0开始的完全矢量表示,而是将相关的矢量之间的距离规范化到长度为一来保存的,同时假设单位圆表示矢量在空间表面的投影。在这种情形下,每一个文件可以一个单一的点描述,而这些点可以用相应文件矢量所形成的那片区域区分。具有相似文件索引项的文件用空间中响铃的两个点表示。简而言之,表示两个文件的点之间在空间中的距离与相应的两个矢量之间的相似度成反相关。由于文件空间的构造是索引项以及其权值对文件集合中每一个不同文件分配的一种函数,所以需要考虑一种...