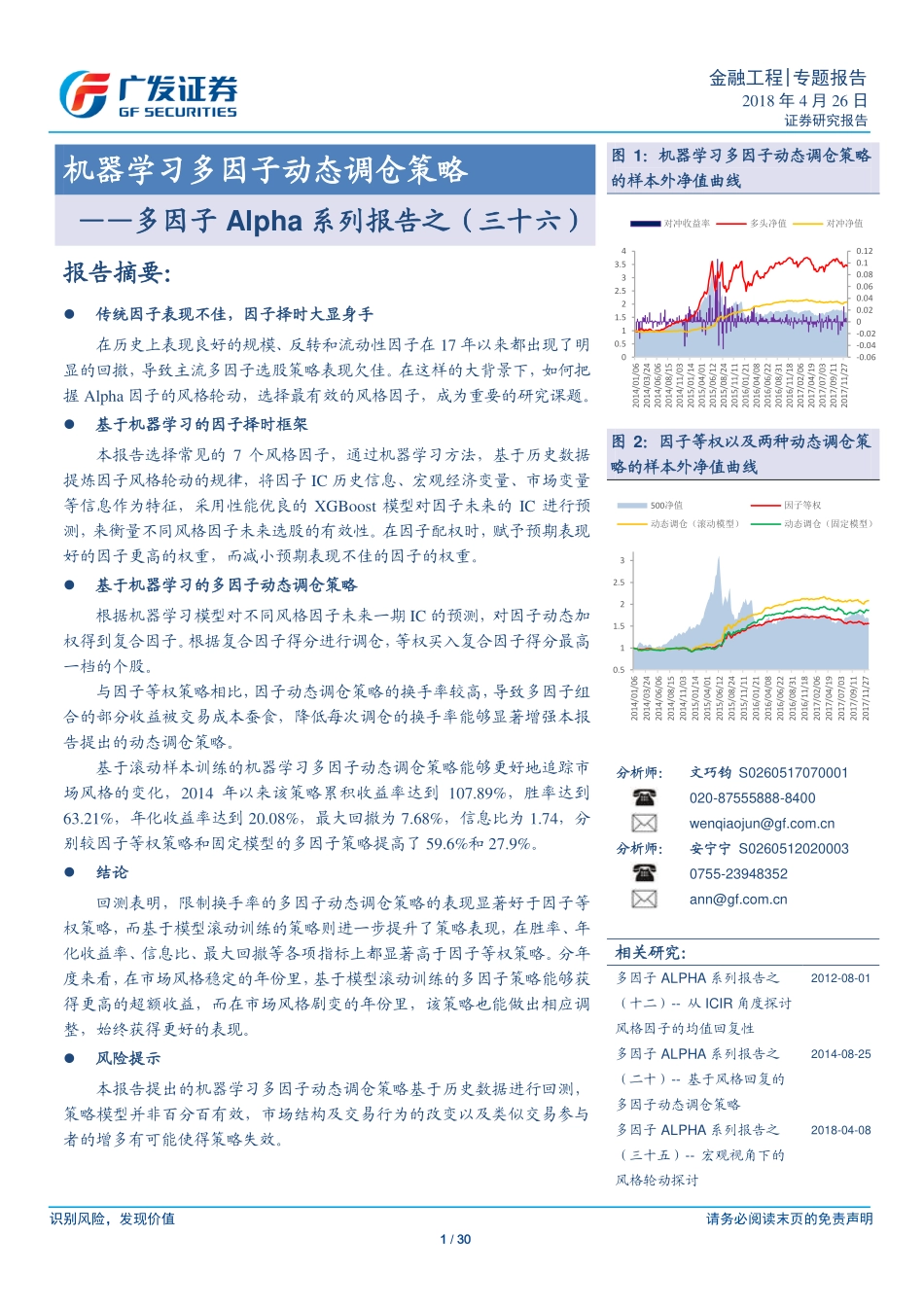
识别风险,发现价值请务必阅读末页的免责声明1/30金融工程|专题报告2018年4月26日证券研究报告Table_Title机器学习多因子动态调仓策略——多因子Alpha系列报告之(三十六)Table_Summary报告摘要:传统因子表现不佳,因子择时大显身手在历史上表现良好的规模、反转和流动性因子在17年以来都出现了明显的回撤,导致主流多因子选股策略表现欠佳。在这样的大背景下,如何把握Alpha因子的风格轮动,选择最有效的风格因子,成为重要的研究课题。基于机器学习的因子择时框架本报告选择常见的7个风格因子,通过机器学习方法,基于历史数据提炼因子风格轮动的规律,将因子IC历史信息、宏观经济变量、市场变量等信息作为特征,采用性能优良的XGBoost模型对因子未来的IC进行预测,来衡量不同风格因子未来选股的有效性。在因子配权时,赋予预期表现好的因子更高的权重,而减小预期表现不佳的因子的权重。基于机器学习的多因子动态调仓策略根据机器学习模型对不同风格因子未来一期IC的预测,对因子动态加权得到复合因子。根据复合因子得分进行调仓,等权买入复合因子得分最高一档的个股。与因子等权策略相比,因子动态调仓策略的换手率较高,导致多因子组合的部分收益被交易成本蚕食,降低每次调仓的换手率能够显著增强本报告提出的动态调仓策略。基于滚动样本训练的机器学习多因子动态调仓策略能够更好地追踪市场风格的变化,2014年以来该策略累积收益率达到107.89%,胜率达到63.21%,年化收益率达到20.08%,最大回撤为7.68%,信息比为1.74,分别较因子等权策略和固定模型的多因子策略提高了59.6%和27.9%。结论回测表明,限制换手率的多因子动态调仓策略的表现显著好于因子等权策略,而基于模型滚动训练的策略则进一步提升了策略表现,在胜率、年化收益率、信息比、最大回撤等各项指标上都显著高于因子等权策略。分年度来看,在市场风格稳定的年份里,基于模型滚动训练的多因子策略能够获得更高的超额收益,而在市场风格剧变的年份里,该策略也能做出相应调整,始终获得更好的表现。风险提示本报告提出的机器学习多因子动态调仓策略基于历史数据进行回测,策略模型并非百分百有效,市场结构及交易行为的改变以及类似交易参与者的增多有可能使得策略失效。图1:机器学习多因子动态调仓策略的样本外净值曲线图2:因子等权以及两种动态调仓策略的样本外净值曲线Table_Author分析师:文巧钧S0260517070001020-87555888-8400wenqiaojun@gf.com.cn分析师:...