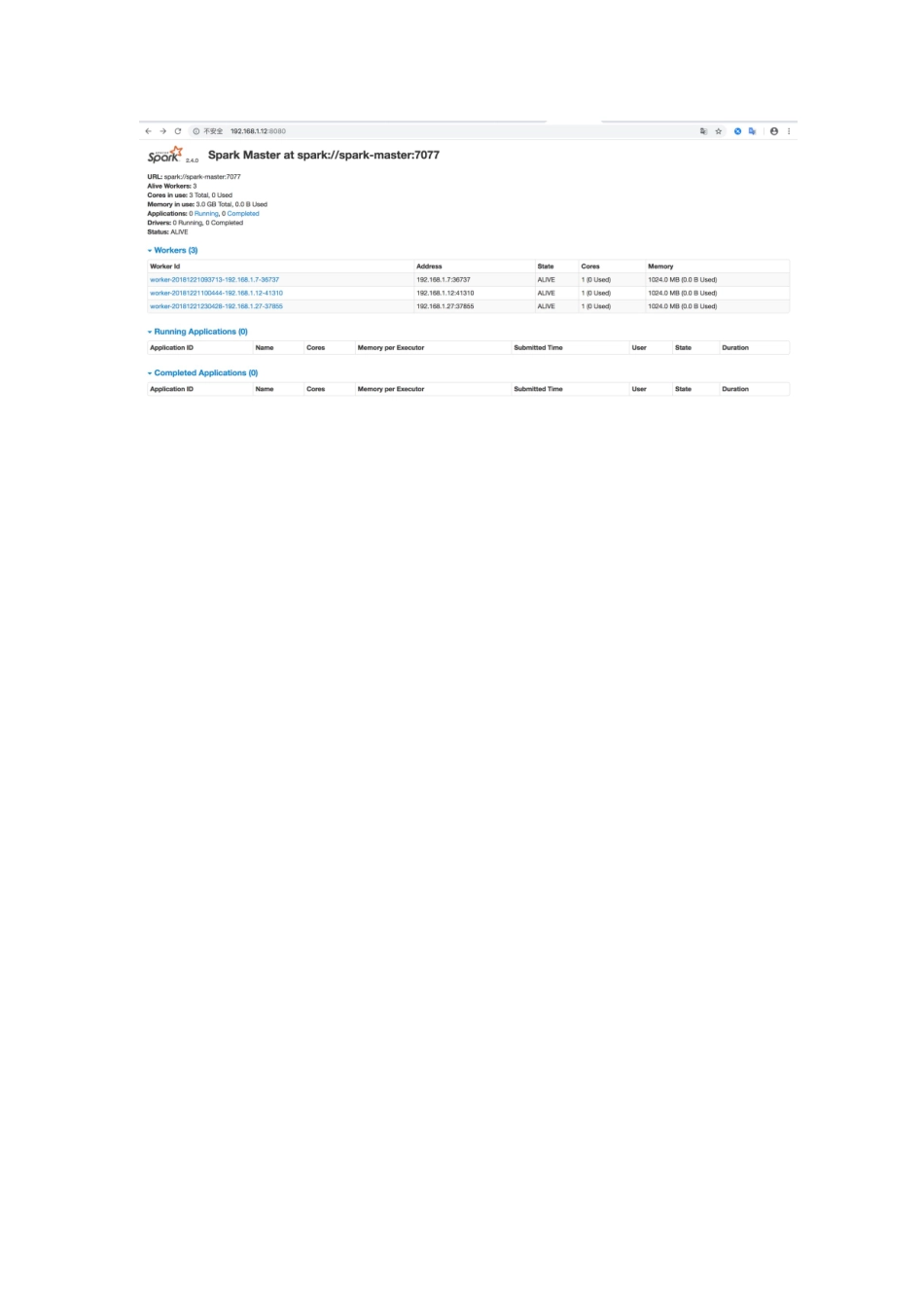
我写的每一个字都要认真读,不然就掉坑里3台linux虚拟机,注意注意注意::::最好都是centos,我挑战了一下两个centos一个ubuntu,结果ubuntu上的worker死活起不来。耗费了好长时间才起来,这里是坑,切记切记!!1、安装配置JDK1.82、安装配置scala3、下载spark(注意注意注意,下载和解压的目录位置要一样,如果不这样做,那么要配置sparkhome)wgethttps://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz4、修改主机名,配置hostsvim/etc/sysconfig/network把内容写进去HOSTNAME=spark-master然后重启,生效。重启后输入hostname,检查是否与自己设置的一致vim/etc/hosts格式:ip主机名192.168.1.12spark-master192.168.1.7spark-slave1192.168.1.27spark-slave25、配置用户useraddsparkpasswdspark回车后添加密码6、master做免登陆:要切换到spark用户下执行主机登陆到另外两个从机上需要免密,所以主机配置即可生成秘钥:ssh-keygen-trsa然后一直回车无秘登陆设置:ssh-copy-id-i~/.ssh/id_rsa.pub192.168.1.7以下是所有服务器都要操作,并且都要用sprak用户操作,只有再解决权限问题的时候才到root下7、复制文件cpspark-2.4.0-bin-hadoop2.7/conf/spark-env.sh.templatespark-env.sh创建文件夹修改vimspark-2.4.0-bin-hadoop2.7/conf/spark-env.sh添加exportJAVA_HOME=/home/jdk1.8.0_181这里是你自己的jdkhomeexportSPARK_MASTER_IP=192.168.1.12这里是主机的ip8、复制conf下的slaves文件cpslaves.templateslaves添加/data/service/bigdata/spark/conf/slaves文件添加主机名称:vimslavesspark-masterspark-slave1spark-slave29、启动服务注意关闭防火墙,不然连不上命令:systemctlstopfirewalldcdspark/sbin/start-all.sh启动所有服务这个命令会自动启动在slave配置下的worker服务(如果这里启动有问题,可手动输入一下密码解决,也可以看一下免密配置)start-slave.shspark://主机名称:7077单独启动某一个workerspark://主机名称:7077是master的连接地址启动成功访问master的ip:8080