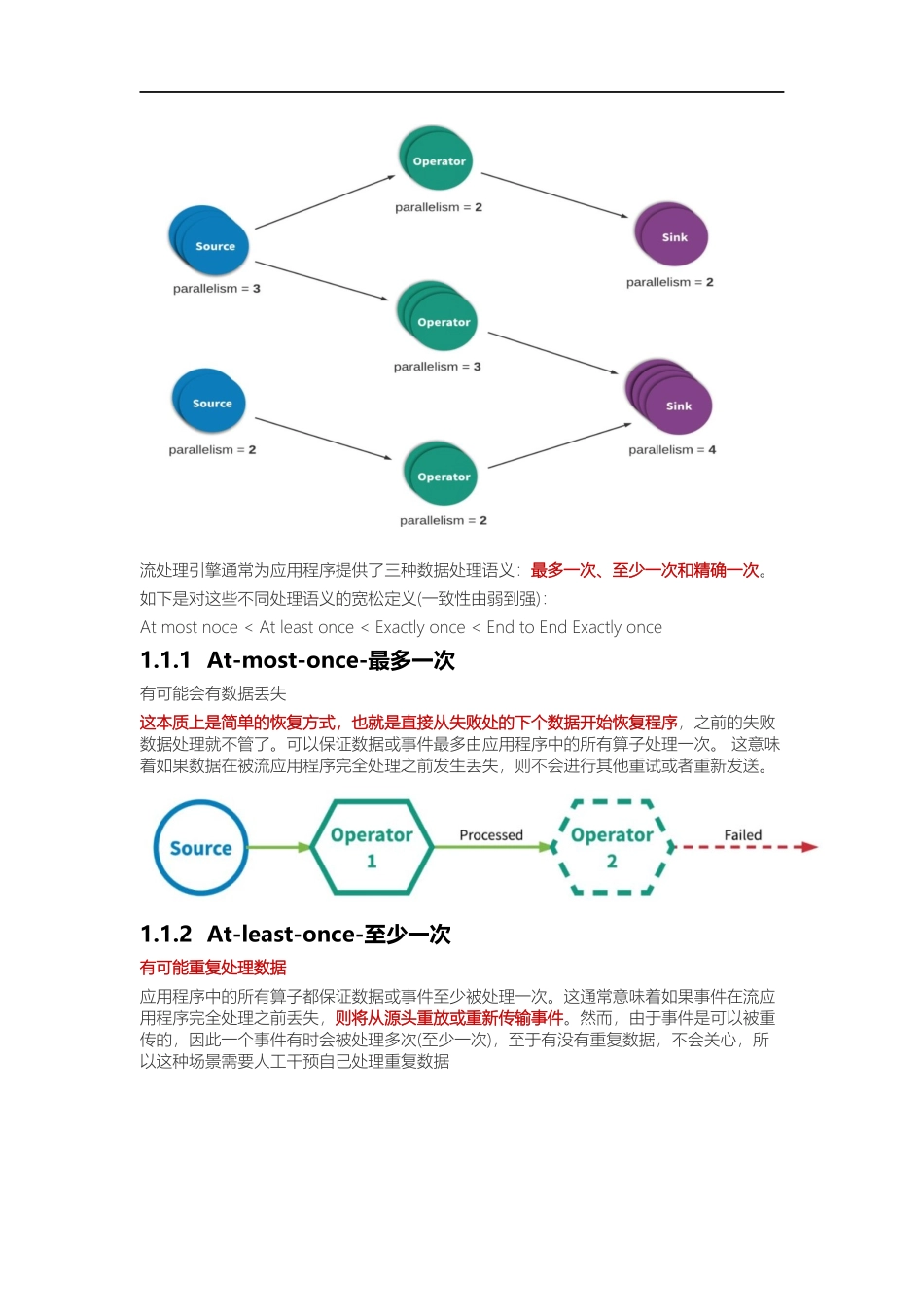
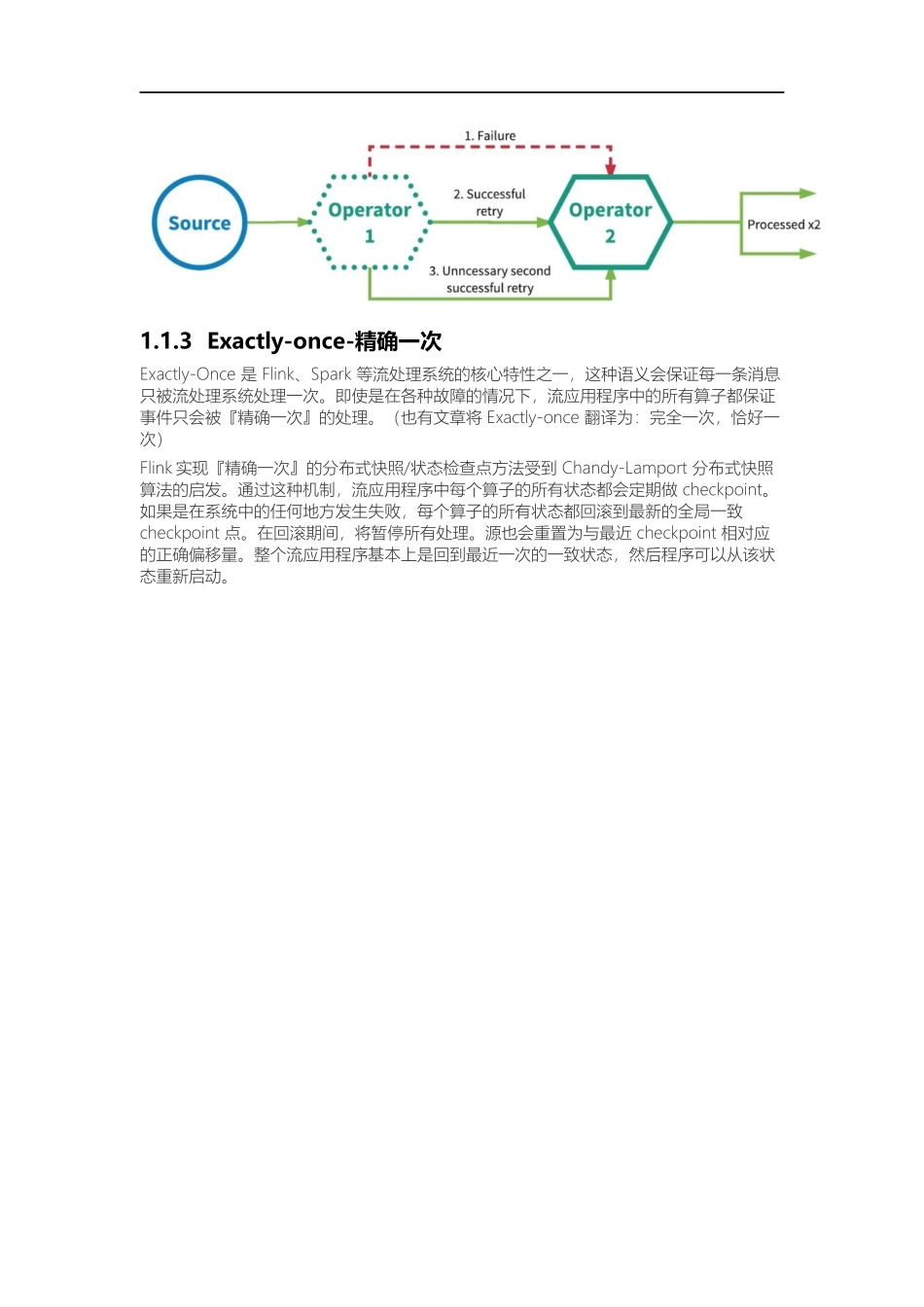
第四章Flink高级特性和新特性课程目标了解流处理的相关概念掌握FlinkDataStream-SourceOperator掌握FlinkDataStream-TransformationOperator掌握FlinkDataStream-SinkOperator了解Flink的累加器掌握Flink的广播变量掌握Flink的分布式缓存1.End-to-EndExactly-OnceFlink在1.4.0版本引入『exactly-once』并号称支持『End-to-EndExactly-Once』“端到端的精确一次”语义。1.1流处理的数据处理语义对于批处理,fault-tolerant(容错性)很容易做,失败只需要replay,就可以完美做到容错。对于流处理,数据流本身是动态,没有所谓的开始或结束,虽然可以replaybuffer的部分数据,但fault-tolerant做起来会复杂的多流处理(有时称为事件处理)可以简单地描述为是对无界数据或事件的连续处理。流或事件处理应用程序可以或多或少地被描述为有向图,并且通常被描述为有向无环图(DAG)。在这样的图中,每个边表示数据或事件流,每个顶点表示运算符,会使用程序中定义的逻辑处理来自相邻边的数据或事件。有两种特殊类型的顶点,通常称为sources和sinks。sources读取外部数据/事件到应用程序中,而sinks通常会收集应用程序生成的结果。下图是流式应用程序的示例。有如下特点:分布式情况下是由多个Source(读取数据)节点、多个Operator(数据处理)节点、多个Sink(输出)节点构成每个节点的并行数可以有差异,且每个节点都有可能发生故障对于数据正确性最重要的一点,就是当发生故障时,是怎样容错与恢复的。流处理引擎通常为应用程序提供了三种数据处理语义:最多一次、至少一次和精确一次。如下是对这些不同处理语义的宽松定义(一致性由弱到强):Atmostnoce