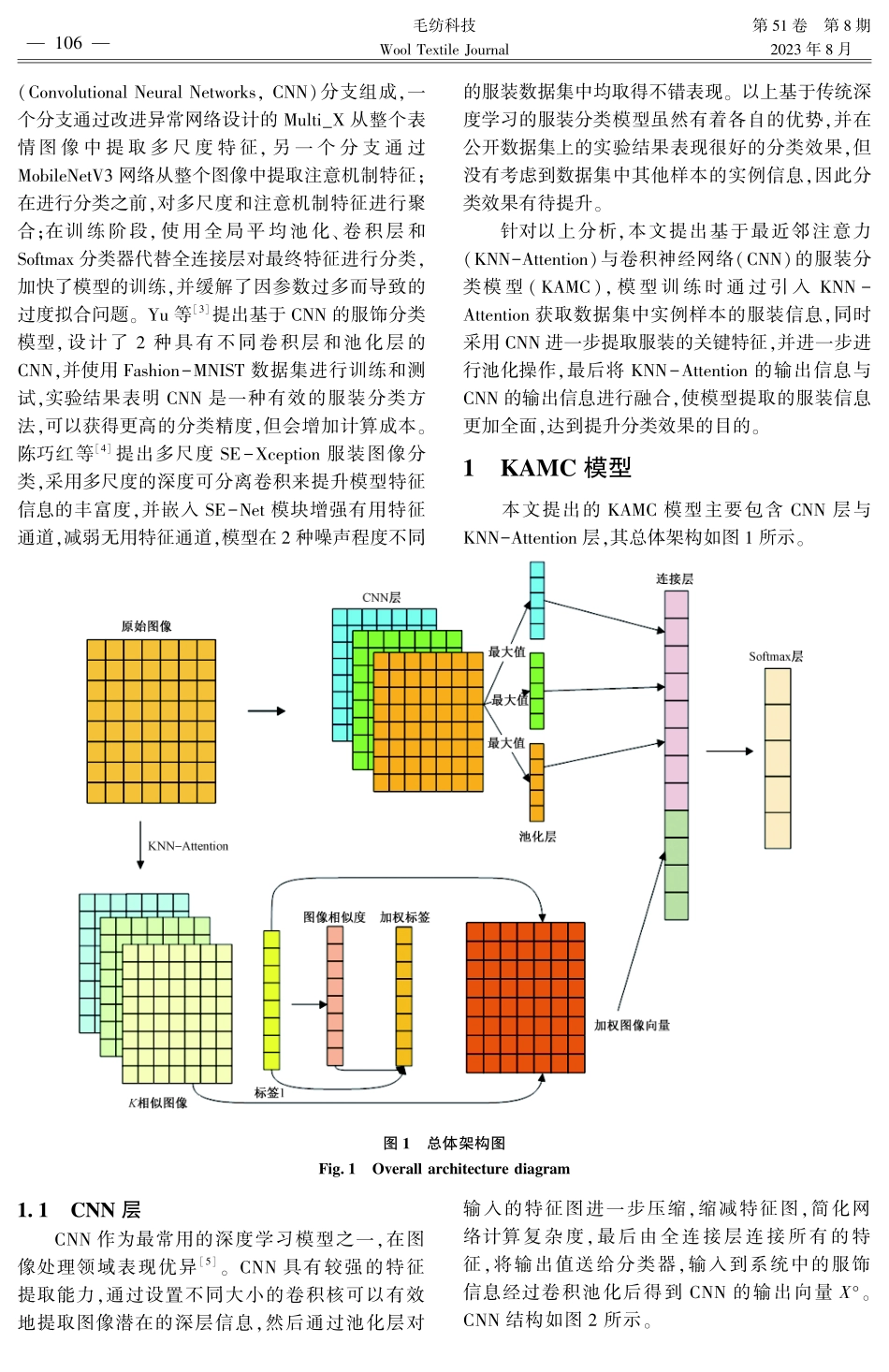
第51卷第8期2023年8月毛纺科技WoolTextileJournalDOI:1019333/j.mfkj.20220702207基于最近邻注意力与卷积神经网络的服装分类模型关紫微1,吕钊1,滕金保2(1.西安工程大学服装与艺术设计学院,陕西西安710048;2.西安邮电大学计算机学院,陕西西安710121)摘要:针对传统的服装分类模型分类时无法有效提取训练集中其他样本的实例信息问题,提出基于最近邻注意力(KNN-Attention)与卷积神经网络(ConvolutionalNeuralNetworks,CNN)的服装分类模型(KAMC)。首先,用KNN-Attention提取与原训练样本相似的实例样本的服装信息;然后用CNN进一步提取服装的局部关键特征;最后融合KNN-Attention和CNN的输出信息,从而在服装分类任务时有效地利用训练集实例信息。以公开的服装数据集进行实验验证,实验结果表明,提出的模型相较于传统的分类模型效果更好,可以有效提高服装的分类效果。关键词:服装分类;最近邻算法;注意力机制;卷积神经网络中图分类号:TS941;TP391文献标志码:AClothingclassificationmodelbasedonKNN⁃AttentionandconvolutionneuralnetworkGUANZiwei1,LÜZhao1,TENGJinbao2(1.Apparel&ArtDesignCollege,Xi′anPolytechnicUniversity,Xi′an,Shaanxi710048,China;2.CollegeofComputer,Xi′anUniversityofPostsandTelecommunications,Xi′an,Shaanxi710121,China)Abstract:Aimingattheproblemthatthetraditionalclothingclassificationmodelcannoteffectivelyextracttheinstanceinformationofothersamplesinthetrainingset,aclothingclassificationmodelbasedonKNN⁃AttentionandConvolutionalNeuralNetworks(CNN...