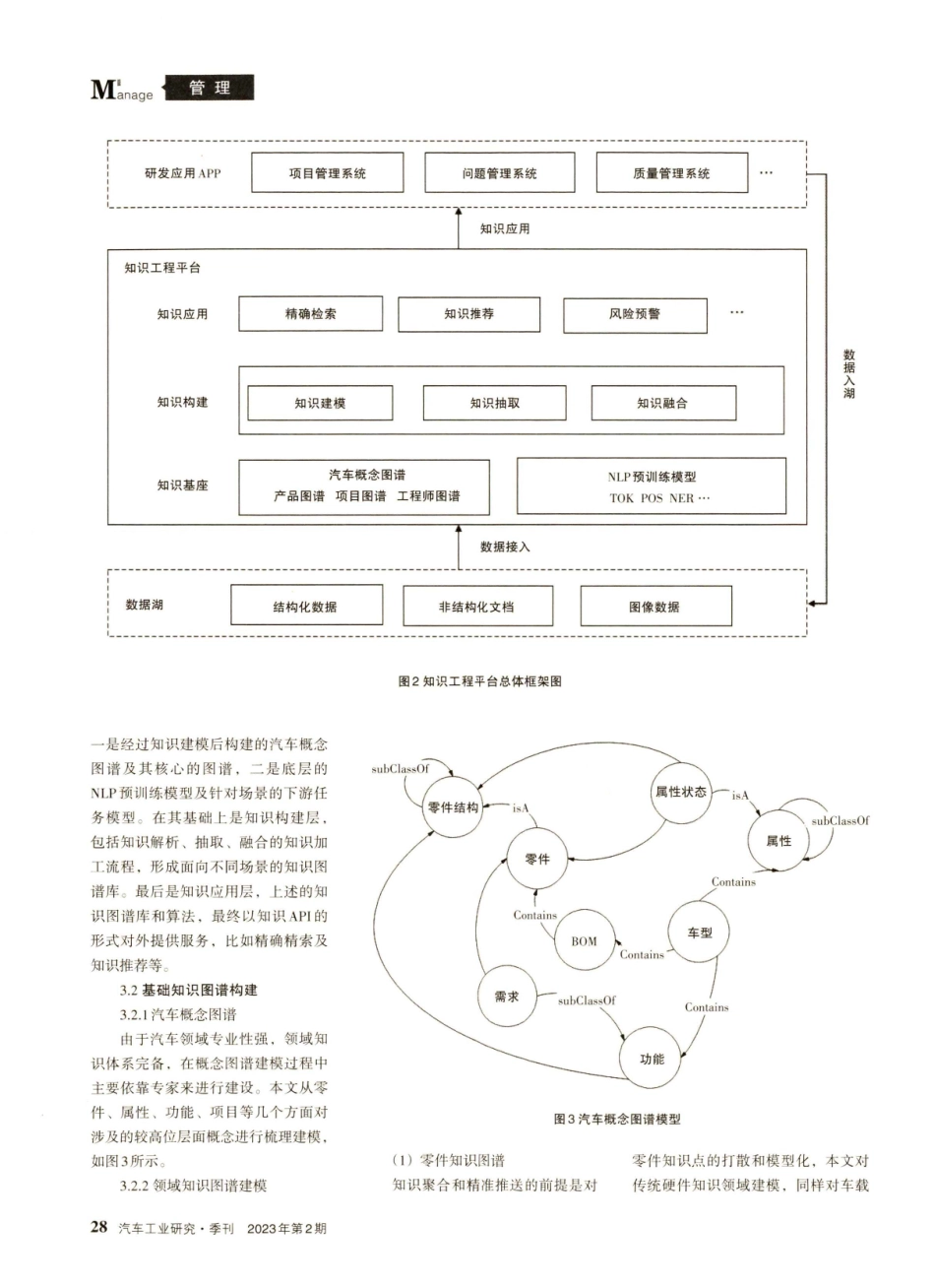
26汽车工业研究·季刊2023年第2期.............管理MLanageDOl:10.3969/j.issn.1009-847X.2023.02.007基于知识图谱技术的汽车研发知识工程平台构建探索陈川张书瑞赵行阳汤慧俊刘旭摘要:汽车行业是一个知识密集型以及技术密集型的行业,汽车行业的知识共享可以有效提升研发效率,进而提升汽车产品竞争力。本文基于知识图谱相关技术,对汽车研发领域专业知识进行建模;建设了该领域的数据集,并在该数据集上微调了命名实体识别、文本蕴含等模型;构建了一整套知识存储、加工、推送及精确检索的知识工程平台,从而实现利用知识共享提升汽车研发质量并加快研发效率的目的。关键词:知识图谱命名实体识别知识工程汽车研发汽车研发有着系统的开发流程,支持这些流程的工作指导手册、指南、工具、检查清单形成一套完整的知识库框架。但是这些知识往往重复出现在不同的文档之中,缺少逻辑关联,使得工程师查找困难,使用效率低,更新成本高。知识工程是知识管理、信息技术和工程应用的交叉学科,其研究的核心是如何高效以及智能化地应用知识。本文尝试利用知识图谱技术将汽车研发知识体系中的流程、标准、规范、检查清单等高质量知识有效连接起来,建立基于图数据模型上的智能知识工程平台,通过知识精确检索和知识推理,嵌人到工程师日常研发工作中去。背景介绍1.1知识图谱简介知识图谱是一种基于大数据的知识工程应用,起源于2012年google对其搜索引擎中图技术的称呼。知识图谱将知识转化为由实体(entity)及属性(property)以及实体之间的关系(relationship)组成的语义网络。如“通风盖板中固定洗涤软管的两卡扣间距≤150mm”这一设计指导类知识,转化为知识图谱可以表达如下页图1所示。这种富含语义信息的知识图谱可以用于表达知识中的整体性和关联性,也可以作为背景知识结合深度学习提升认知智能。1.2汽车行业的应用当前知识图谱应用于汽车研发知识工程主要有两个方向,一是将专业领域内的知识构建成图谱,以知识精确检索、知识推理等方式提供服务,主要解决专业领域内知识共享难和效率低等问题;如黄巍等利用知识图谱技术构建了汽车维修场景知识图谱2;娄璇构建了自动变速器知识图谱,包含零部件及其设计参数和计算公式之间的关系,基于知识推理实现设计变更过程中的自动验证3。另外一种方向是基于当前汽车行业通用知识构建图谱,利用最新的行业研究成果,通过构建技术专家模型,发掘创新技术热点支撑前瞻技术规划;也有众多学者利用Citaspace以及Vo...