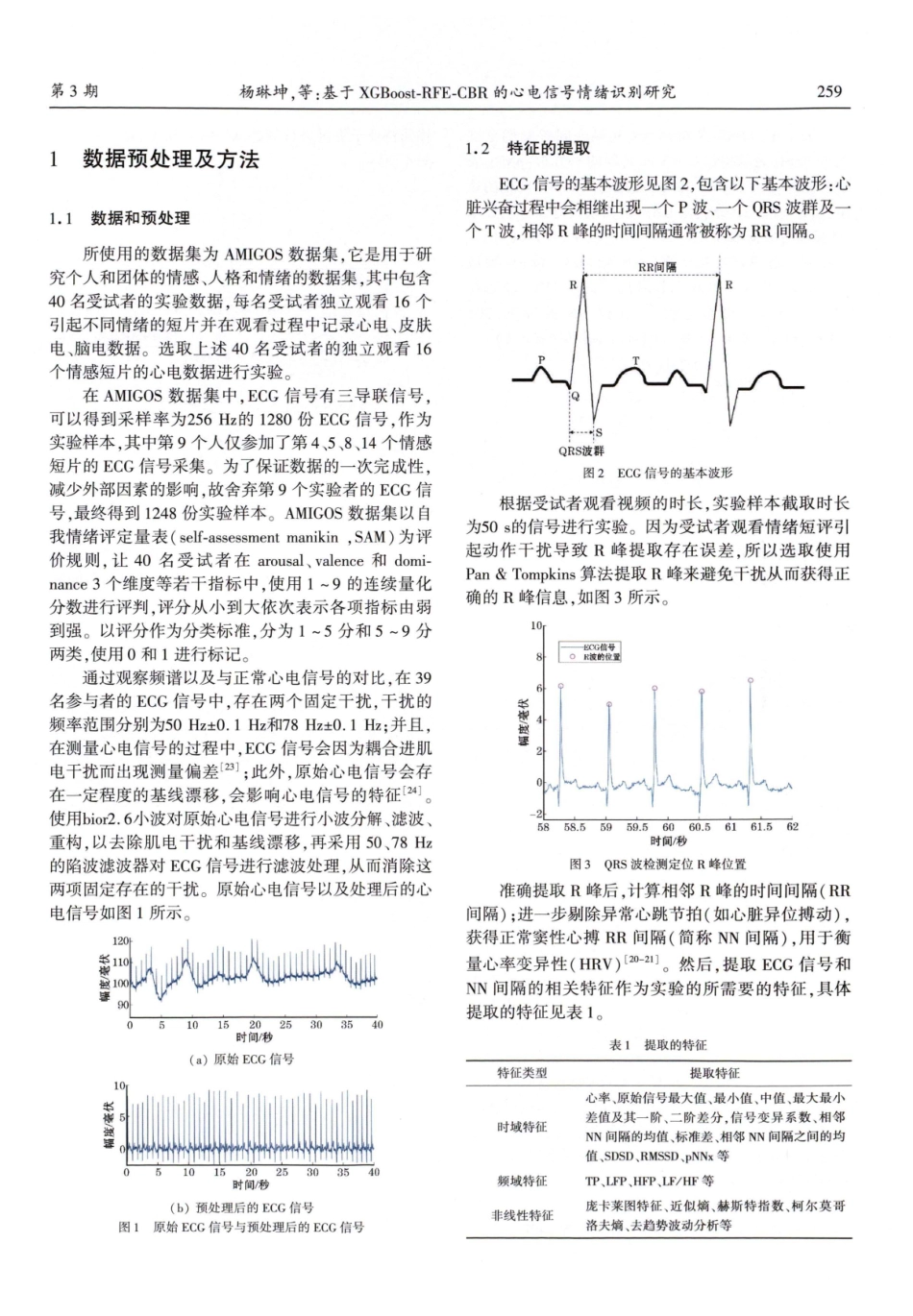
Jun.2023JOURNALOFCHENGDUUNIVERSITYOFINFORMATIONTECHNOLOGY2023年6月Vol.38No.3息第38卷第3期工程成报大学学都信文章编号:2096-1618(2023)03-0258-06基于XGBoost-RFE-CBR的心电信号情绪识别研究杨琳坤,何培宇,潘帆,方安成(四川大学电子信息学院,四川成都610065)摘要:情绪是一种复杂的行为现象,是对不同外部刺激的生理反应。为快速、便捷地识别人类的情绪,提出了一种基于极限梯度提升结合可减少相关性偏差和递归特征消除的心电信号情绪识别方法。先对AMIGOS数据集进行特征提取、结合XGBoost-RFE-CBR特征排序算法进行特征选择,得到27个心电信号和心率变异性的时域、频域等特征参数,利用XGBoost进行分类,最后在五折交叉验证下,最高准确率达80.5%、平均准确率达77.2%。该方法与多维生理信号特征提取方法相比,在确保准确率的同时降低了计算量,对情绪识别和分类任务有一定的参考价值。关键词:信号与信息处理;情绪识别;心电信号;极限梯度提升;特征选择;递归特征消除中图分类号:TP911.7文献标志码:Adoi:10.16836/j.cnki.jcuit.2023.03.0020引言情绪是人类思想、情感和行为的结合,是对不同外部刺激的生理反应[1]。近年来,情绪识别引起了广泛关注。为此,提出了许多研究方法以准确识别人类情绪,这些研究方法主要可以分为两大类:第一类基于非生理数据的方法,利用语言和面部表情等[2-5]数据判断情绪。这类方法的优点是数据很容易收集,不需要任何专门和昂贵的设备。但是非生理信号可以被主观意愿控制[6],这意味着受试者可以掩盖自己的情绪,并在分类中造成无法检测和消除的不确定性。第二类依据生理数据,如脑电图(electroencephalogram,EEG)[7-8]、肌电图(electromyogram,EMG)i9-10)、心电图(electrocardiogram,ECC)iu1-2]/皮肤电反应(galvan-icskinresponse,CSR)[13-14]等无法人为干预的生理信号作为依据进行情绪判断。这类方法可以更好地与实际情绪状态相关联,但实验的设置较为困难。例如,采集脑电图生理信号需要受试者处于防止外界交流电噪声干扰的屏蔽室,并且对受试者有一定的要求,同时其信号中固有的噪声也会阻碍可靠的情绪识别。两种方法相比之下,第二类方法具有更高的准确性和客观性,并且不限制使用人群。因此,基于生理信号的情绪识别法具有更高的研究价值和实用价值。Kim等[15]提出了用于识别情绪的基于卷积长短期记忆的深层生理影响网络,在DEAP数据集上检测,准确率相较于DEAP实验结果提升了15.96%;陈沙利等...