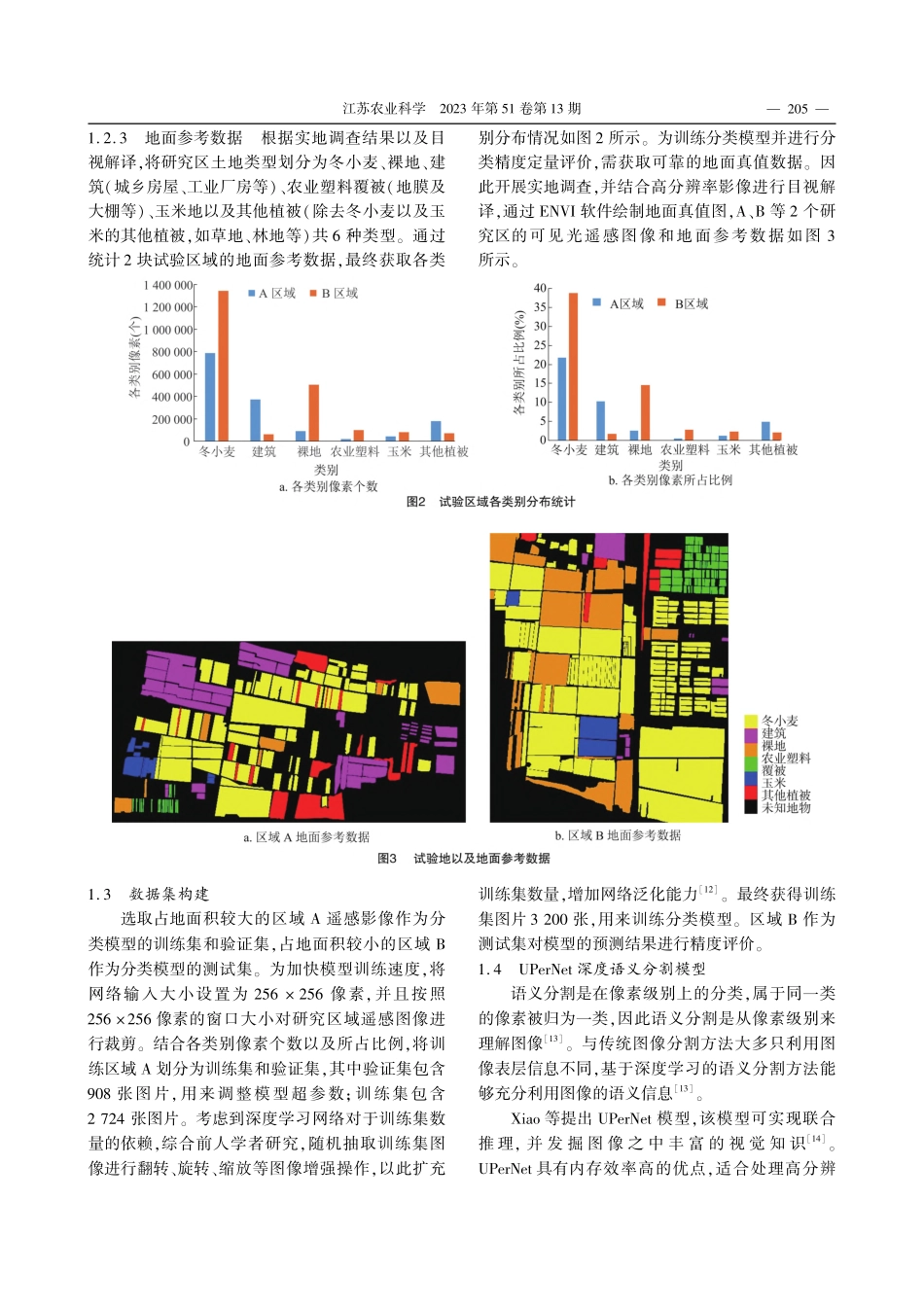
白静远,宁纪锋,郭交,等.基于改进UPerNet和国产高分遥感数据的冬小麦种植区提取[J].江苏农业科学,2023,51(13):203-212.doi:10.15889/j.issn.1002-1302.2023.13.031基于改进UPerNet和国产高分遥感数据的冬小麦种植区提取白静远1,宁纪锋1,2,郭交2,杨蜀秦2,张智韬3(1.西北农林科技大学信息工程学院,陕西杨凌712100;2.陕西省农业信息感知与智能服务重点实验室,陕西杨凌712100;3.西北农林科技大学水利与建筑工程学院,陕西杨凌712100)摘要:遥感技术能够获取大区域下冬小麦的空间分布,为冬小麦估产提供良好基础。基于2020年5月4日的高分2号多光谱卫星影像,构建包含光谱特征和植被指数的数据集,并通过改进UPerNet模型的上采样结构、激活函数以及增加注意力模块来优化模型提取冬小麦效果。选取杨凌示范区2块地物类型丰富地区作为研究区域,以此探究方法的可行性;然后基于最优方法,提取杨凌区冬小麦种植区域。研究区域结果表明,与仅使用光谱信息作为模型输入特征相比,基于多光谱和植被指数的分类效果更好。在融合光谱特征和植被指数的数据集上,改进的UPerNet模型分类精度最高,冬小麦提取精度为97.78%,总体分类精度相比于改进前的UPerNet提升了2.49%,对比DeepLabV3+提升了3.48%。基于改进方法,实现了杨凌示范区的冬小麦种植区提取;通过实地调查以及对比统计年鉴数据的方式,验证了杨凌示范区冬小麦空间分布与实际情况基本一致。改进后的UPerNet模型能够有效区分遥感数据中的地物类别,提升冬小麦种植区域提取精度,也为基于卫星影像获取冬小麦空间分布提供了技术支持。关键词:冬小麦;种植区提取;语义分割;高分卫星;UPerNet中图分类号:S127文献标志码:A文章编号:1002-1302(2023)13-0203-09收稿日期:2022-10-04基金项目:陕西省自然科学基础研究计划(编号:2022JM-128)。作者简介:白静远(1998—),男,陕西蒲城人,硕士研究生,从事卫星遥感图像分类等研究。E-mail:a820439612@nwafu.edu.cn。通信作者:宁纪锋,博士,教授,从事计算机视觉、模式识别和机器学习研究。E-mail:njf@nwsuaf.edu.cn。冬小麦是我...