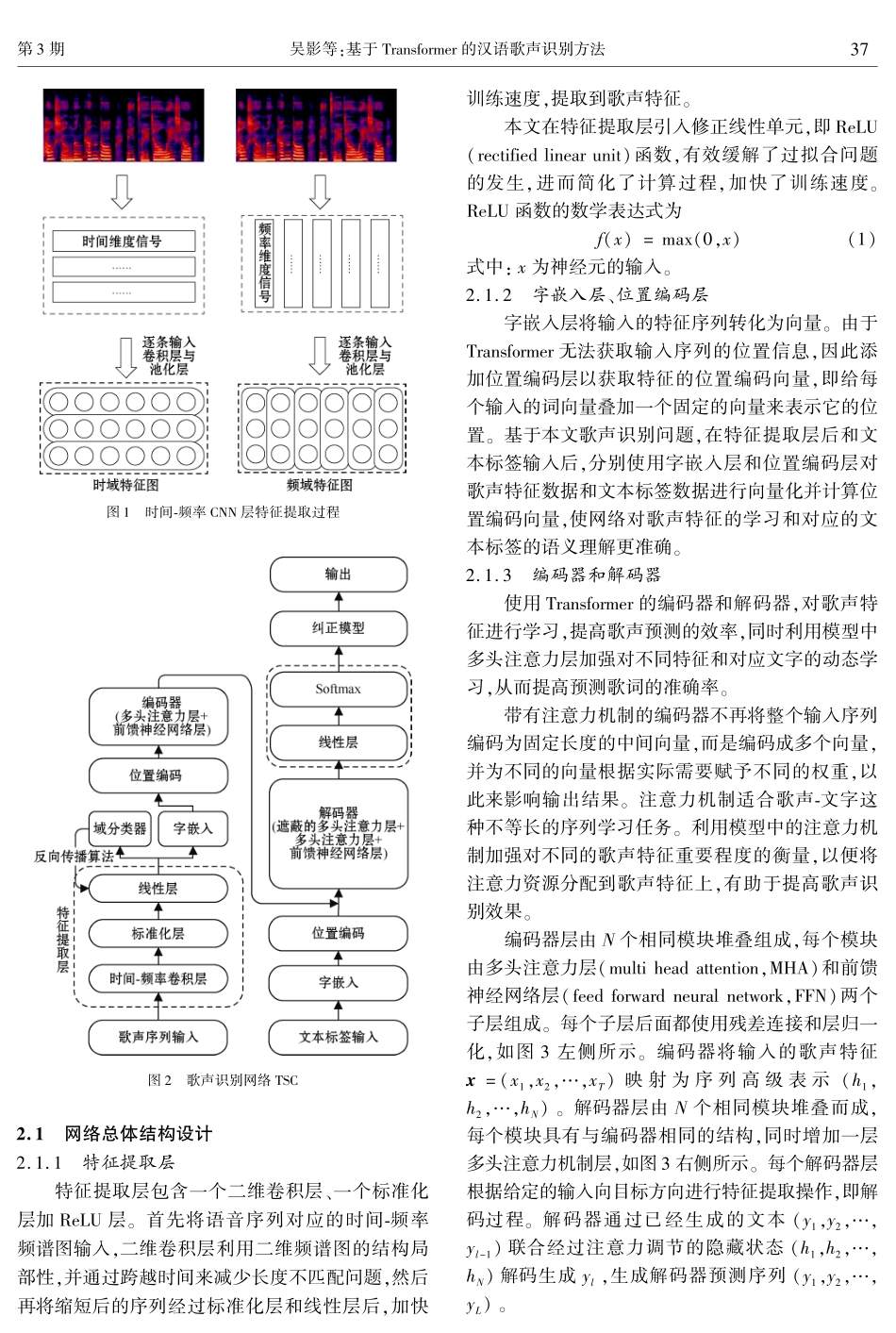
第38卷第3期2023年6月北京信息科技大学学报JournalofBeijingInformationScience&TechnologyUniversityVol.38No.3Jun.2023文章编号:1674-6864(2023)03-0035-08DOI:1016508/j.cnki.11-5866/n.202303006基于Transformer的汉语歌声识别方法吴影1ꎬ2ꎬ徐雅斌1ꎬ2ꎬ3ꎬ孟晶晶1ꎬ2(1.北京信息科技大学网络文化与数字传播北京市重点实验室ꎬ北京100101ꎻ2.北京信息科技大学计算机学院ꎬ北京100101ꎻ3.北京信息科技大学大数据安全技术研究所ꎬ北京100101)摘要:为提高歌声识别准确率ꎬ提出一种基于Transformer并带有纠正模型的歌声识别方法TSC(transformerwithspellingcorrection)ꎮ利用注意力机制ꎬ使网络学习对应的歌词发音ꎮ在模型输入模块ꎬ增加由卷积神经网络组成的特征提取层ꎬ提取歌声特征ꎮ在输出模块后面ꎬ增加由卷积神经网络和双向循环神经网络组成的纠正模型ꎬ修正模型的输出结果ꎮ针对歌声样本量较少ꎬ模型训练困难的问题ꎬ提出了使用汉语语音数据集AISHELL ̄1进行预训练ꎬ并自制一组数据进行数据增强ꎬ对歌声识别模型参数进行微调ꎮ在增强的Opencpop歌声数据集上进行实验的结果表明ꎬ提出的歌声识别系统的字错率降低到了31.92%ꎮ关键词:Transformerꎻ迁移学习ꎻ汉语歌声识别ꎻ拼写纠正中图分类号:TP183文献标志码:AChinesesungspeechrecognitionmethodbasedonTransformerWUYing1ꎬ2ꎬXUYabin1ꎬ2ꎬ3ꎬMENGJingjing1ꎬ2(1.BeijingKeyLaboratoryofInternetCultureandDigitalDisseminationResearchꎬBeijingInformationScience&TechnologyUniversityꎬBeijing100101ꎬChinaꎻ2.ComputerSchoolꎬBeijingInformationScience&TechnologyUniversityꎬBeijing100101ꎬChinaꎻ3.BigDataSecurityTechnologyResearchI...