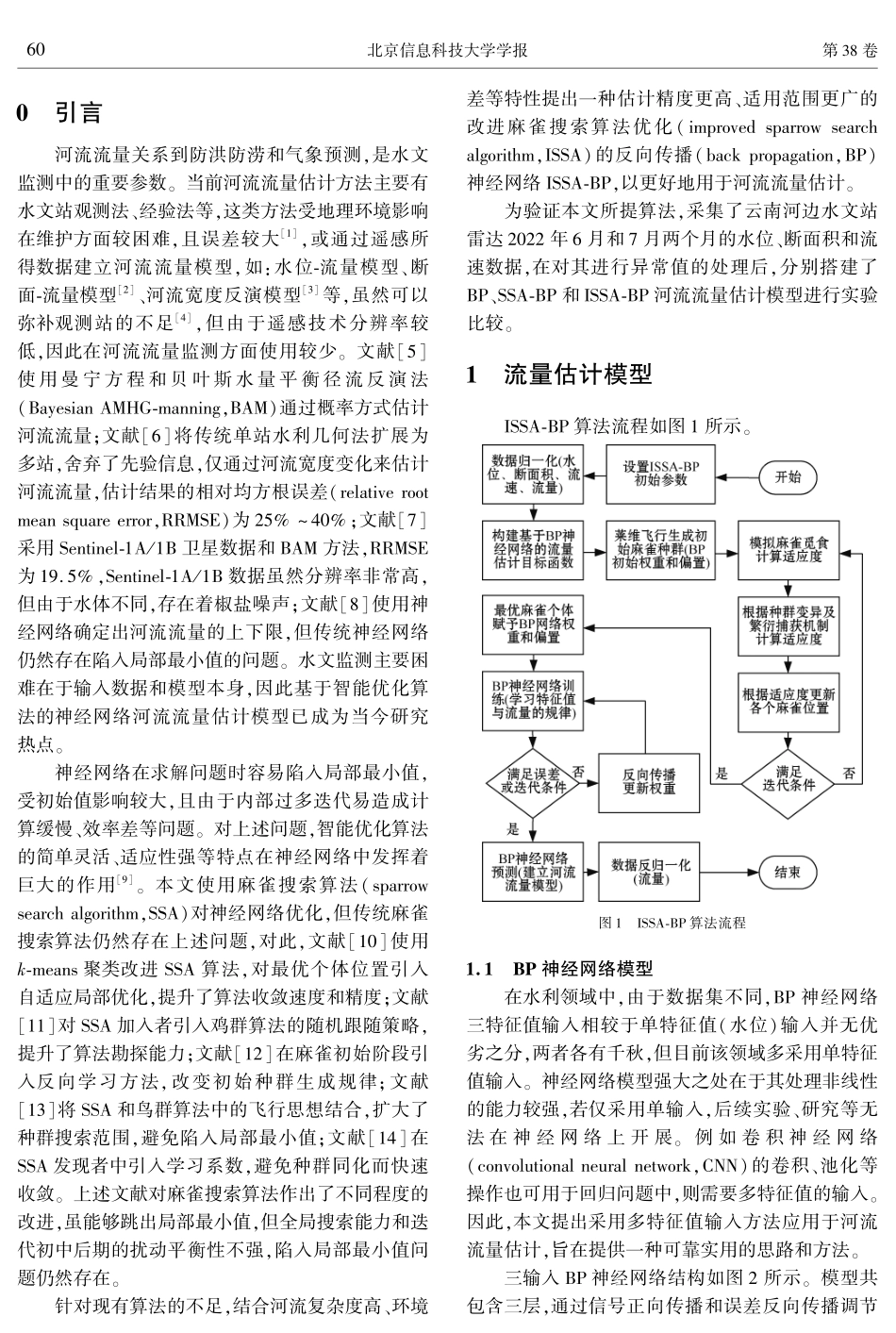
第38卷第3期2023年6月北京信息科技大学学报JournalofBeijingInformationScience&TechnologyUniversityVol.38No.3Jun.2023文章编号:1674-6864(2023)03-0059-07DOI:1016508/j.cnki.11-5866/n.202303009多输入优化神经网络河流流量估计算法许荆ꎬ张文鑫ꎬ杨鸿波ꎬ李健ꎬ于然(北京信息科技大学自动化学院ꎬ北京100192)摘要:针对传统模型在河流流量估计方面精度低、自适应能力差、易陷入局部最小值的问题ꎬ提出一种改进麻雀搜索算法(improvedsparrowsearchalgorithmꎬISSA)优化反向传播(backpropagationꎬBP)神经网络的算法ꎬ利用雷达采集的河流水位、断面积、流速对河流流量进行估计ꎮ针对麻雀搜索算法(sparrowsearchalgorithmꎬSSA)易陷入局部极值问题进行改进ꎬ通过莱维飞行对SSA初始个体优化ꎬ从而提高种群多样性ꎻ引入捕获繁衍机制至麻雀发现者中ꎬ以便麻雀个体能够最大程度搜索且提高其跳出局部最优的能力ꎻ使用基于适应度的差分变异算法对麻雀加入者进行优胜劣汰的选择ꎬ以提高流量估计的准确性和稳定性ꎮ使用云南河边水文站2022年6月和7月两个月的数据ꎬ搭建了ISSA ̄BP、SSA ̄BP和BP神经网络进行对比ꎮ实验结果表明ꎬISSA ̄BP较SSA ̄BP和BP平均绝对误差(meanabsoluteerrorꎬMAE)分别降低了25.5%和40.2%ꎬ证实了该算法在多特征值河流流量估计方面具有较好的可行性和性能ꎮ关键词:神经网络ꎻ麻雀搜索算法ꎻ莱维飞行ꎻ差分变异ꎻ捕获繁衍机制ꎻ河流流量ꎻ估计中图分类号:TN958.6文献标志码:ARiverflowestimationalgorithmbasedonmulti ̄inputoptimizationneuralnetworkXUJingꎬZHANGWenxinꎬYANGHongboꎬLIJianꎬYURan(SchoolofAutomationꎬBeijingInformationScience&TechnologyUniversityꎬBeijing100192ꎬChina)Abstract:Toaddresstheproblemoflowaccuracyꎬpooradaptive...