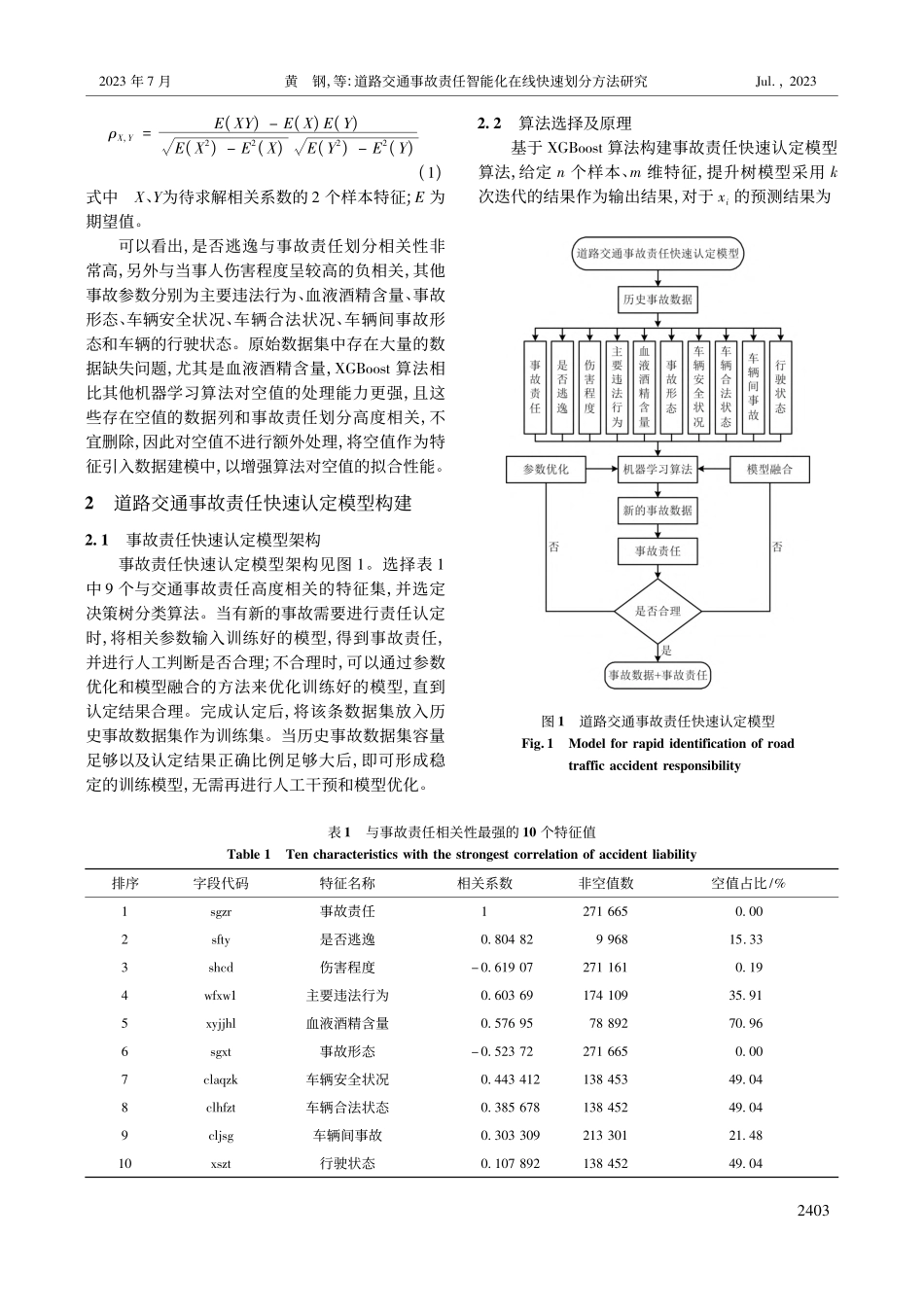
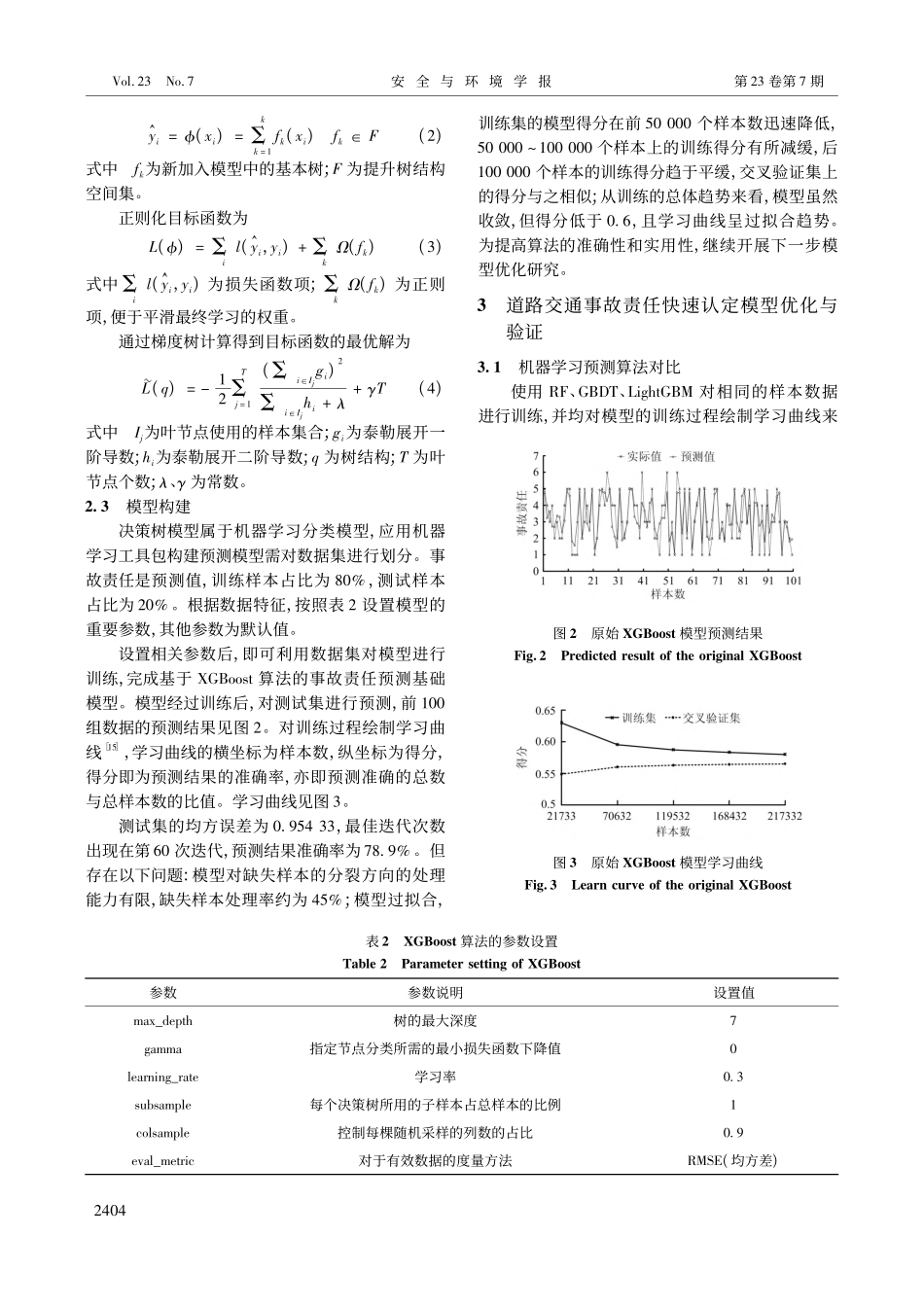
文章编号:1009-6094(2023)07-2402-07道路交通事故责任智能化在线快速划分方法研究*黄钢1,2,李平凡1,3,高岩1,2,孙川4,5(1公安部交通管理科学研究所,江苏无锡214151;2道路交通安全公安部重点实验室,江苏无锡214151;3道路交通集成优化与安全分析技术国家工程实验室,江苏无锡214151;4清华大学苏州汽车研究院(相城),江苏苏州215134;5香港理工大学土木与环境工程系,香港)摘要:为提高智慧交管建设水平,提升执法效率、降低执法成本,对交通事故中当事人责任智能快速划分进行研究。使用Pearson相关系数来计算全部特征与事故责任的相关系数,挑选出与事故责任划分高度相关的数据特征;基于道路交通事故数据及挑选出与事故责任划分明显相关的10个因素为评价指标,使用高效梯度提升决策树(XGBoost)算法对事故责任进行建模预测,结果相对准确,为78.9%,但存在模型对缺失样本分裂方向的处理能力有限及模型过拟合问题;通过参数优化和模型融合方法对XGBoost算法进行优化。结果表明:优化后的算法能有效地自动学习出缺失样本的分裂方向,模型融合对缺失值的处理率已提升至94.8%,处理率提升了50%,缺失样本的分裂方向通过模型融合基本全部得到有效学习,预测结果对比原始算法准确度提升至87.2%,交叉验证结果也表明该算法在交通事故责任智能认定中的适用性。关键词:公共安全;道路交通安全;机器学习;XGBoost;事故责任认定中图分类号:X951文献标志码:ADOI:10.13637/j.issn.1009-6094.2021.2231*收稿日期:2022-02-18作者简介:黄钢,助理研究员,硕士,从事交通事故分析、交通安全研究,hgtmri@126.com;孙川(通信作者),高级工程师,博士,博士后,从事智能交通、交通安全研究,sunchuan@tsari.tsinghua.edu.cn。基金项目:国家自然科学基金项目(52002215);香江学者计划项目(XJ2021028)0引言道路交通事故责任认定是道路交通事故处理中非常重要的环节,认定结果关乎事故当事人刑事、民事处罚决议[1]。交通事故责任认定分为全责、主责、同责、次责和无责5种情况。在实际工作中责任认定结果易受办案民警的业务素养及主观认知的影响,进而会形成“类案异判”的困境。随着“智慧交管”的大力建设,5G、图像处理、语音识别、边缘计算等相关技术迅速发展,在云端完成道路交通事故责任在线快速认定已成为可能[2-5]。交通事故责任认定是一种典型的决策树分类模型[6-7]。Evans等[8]将随机森林(RandomForest,RF)算法应用在交通事件检测中,检测结果...