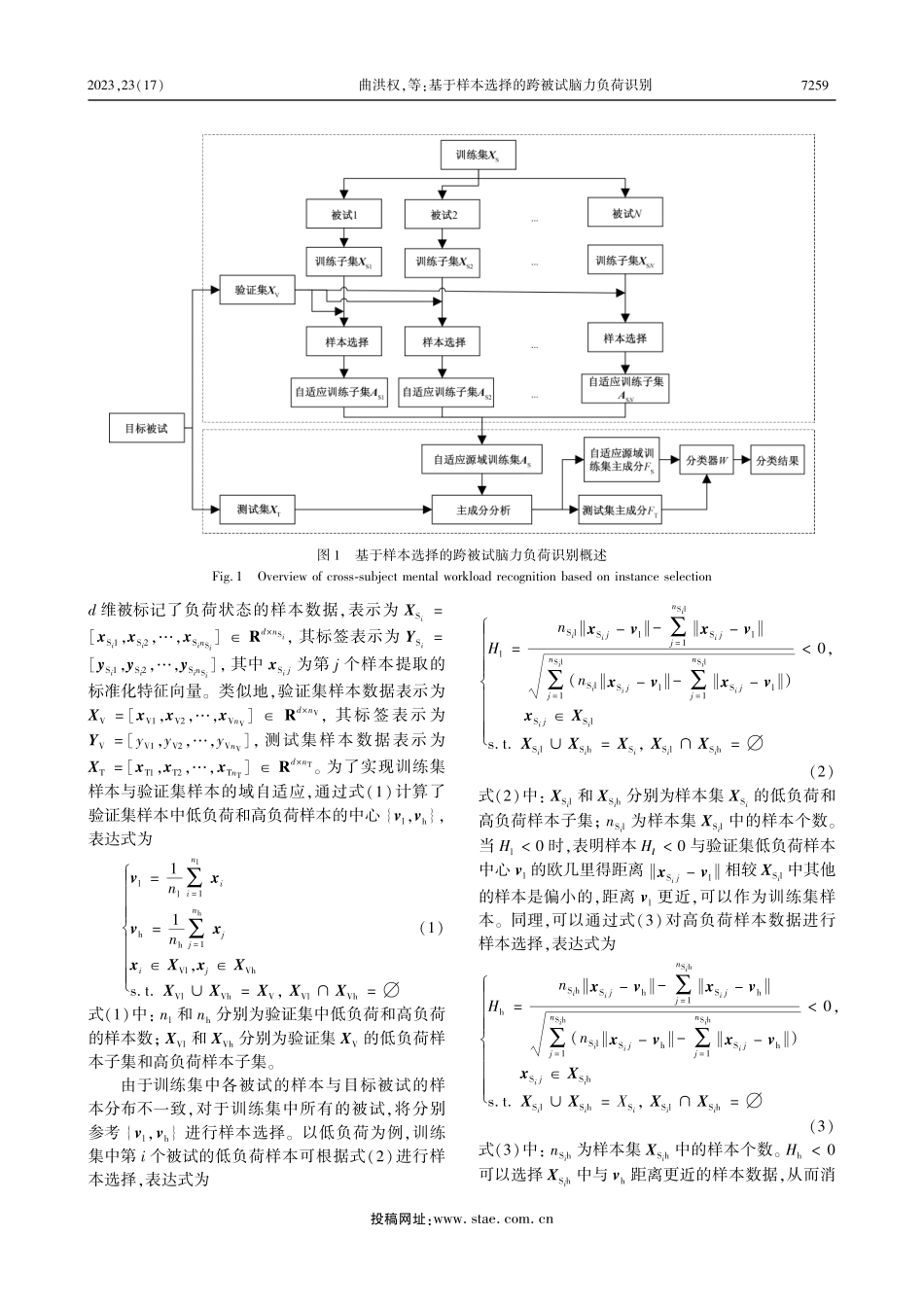
投稿网址:www.stae.com.cn2023年第23卷第17期2023,23(17):07257⁃07科学技术与工程ScienceTechnologyandEngineeringISSN1671—1815CN11—4688/T引用格式:曲洪权,王飞月,庞丽萍,等.基于样本选择的跨被试脑力负荷识别[J].科学技术与工程,2023,23(17):7257⁃7263.QuHongquan,WangFeiyue,PangLiping,etal.Cross⁃subjectmentalworkloadrecognitionbasedoninstanceselection[J].ScienceTechnol⁃ogyandEngineering,2023,23(17):7257⁃7263.医药、卫生基于样本选择的跨被试脑力负荷识别曲洪权1,王飞月1,庞丽萍2∗,陈丽莉3,刘晓花4(1.北方工业大学信息学院,北京100144;2.北京航空航天大学航空科学与工程学院,北京100191;3.华北石油通信有限公司万庄通信总站,廊坊065000;4.中国石油管道局工程有限公司国际事业部,廊坊065000)摘要人体的脑力负荷状态与人机操作工作时的工作效率、人力资源分配以及事故的发生等息息相关,因此研究操作人员的脑力负荷状态具有重要意义。为了解决现有脑力负荷识别方法由于训练集中样本数量过少导致分类效果较差的问题,提出了一种基于样本选择的跨被试脑力负荷识别方法。首先,将其他被试的脑电数据作为训练集,参考目标被试的少量历史数据对训练集中的特征数据进行样本选择,实现减少样本数量的同时减少训练集和测试集之间的域差异;其次,再通过主成分分析对样本选择后的自适应训练集和目标被试测试集特征进行特征降维;最后,用自适应训练集主成分建立支持向量机分类模型识别测试集样本的脑力负荷状态。结果表明,该方法可以在提高分类效率的同时提高分类精度,实现快速、准确的脑力负荷状态识别。关键词样本选择;主成分分析;支持向量机;脑力负荷;脑电中图法分类号R338.8;文献标志码A收稿日期:2022⁃06⁃22;修订日期:2023⁃03⁃23基金项目:辽宁省兴辽英才计划(XLYC1802092)第一作者:曲洪权(1973—),男,汉族,黑龙江青冈人,博士,教授。研究方向:数据科学。E⁃mail:qhqphd@ncut.edu.cn。∗...