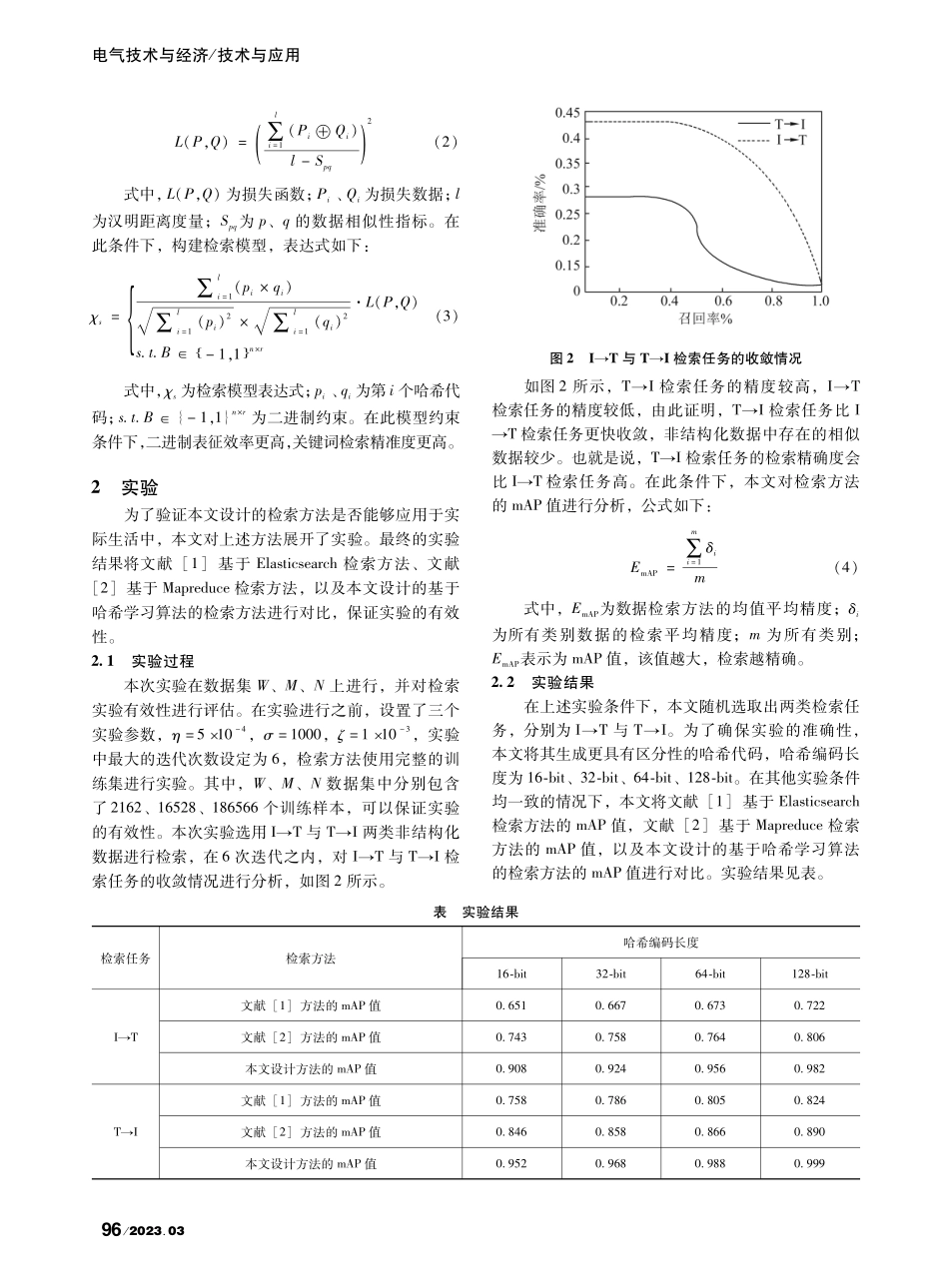
2023.03/基于哈希学习算法的非结构化数据检索方法廖祟阳余少锋严鑫钟建栩席凌之(南方电网调峰调频发电有限公司信息通信分公司)摘要:常规的数据检索方法主要根据数据语意划分检索类别,不完整的数据很难根据语意划分,导致检索mAP值降低。因此,设计了基于哈希学习算法的非结构化数据检索方法。提取非结构化数据的关键词,剔除多余符号与停用词,并对数据中的词频进行分析,便于后续检索。利用哈希学习算法,构建非结构化数据检索模型,将非结构数据按照固有结构检索,并根据相似数据表征剔除相似数据,最大限度地提高数据检索精准度。采用对比实验的方式,验证了该检索方法的mAP值更高,检索效果更佳,能够应用于实际生活中。关键词:哈希学习算法;非结构化数据;检索方法;关键词;检索模型;mAP值0引言非结构化数据就是不完整或无规则的数据,在检索过程中较为困难。针对此类数据,研究人员设计了多种解决方法。其中,基于Elasticsearch的非结构化数据检索方法,与基于Mapreduce的非结构化数据检索方法的应用较为广泛。基于Elasticsearch的非结构化数据检索方法,主要是利用开源软件构建数据库,在数据库中对数据进行语义检索,提高检索效率[1]。基于Mapreduce的非结构化数据检索方法,主要是利用矩阵分解的方法,将非结构化数据转变为中间变量,从而找出数据间存在的联系,通过相似度计算的方式提高检索效率[2]。以上两种方法均能够进行数据高效检索,但是检索准确度相对较低。哈希学习算法,主要是利用哈希代码进行学习,利用哈希函数将数据编码,能够提高检索精准度[3]。因此,本文结合哈希学习算法,设计了非结构化数据检索方法。1非结构化数据的哈希学习算法检索设计1.1提取非结构化数据的关键词数据检索在本质上属于利用相似性查找问题,使用检索方法检索出的数据能够帮助人们快速得到答案[4]。本文将非结构化的数据按照文本、信息等架构进行分类,提取出来的数据存在大量的符号与词条,不具有代表文本的关键信息[5]。因此,本文在进行关键词提取的过程中,剔除多余符号与停用词之后,对数据中的关键词出现的频率进行分析,公式如式(1)所示。Tij=nij∑knkj(1)式中,Tij为关键词的词频;nij为词条i在数据j中出现的次数;nkj为第k类的词条在数据j中出现的次数。Tij值越大,证明该关键词出现在用户的检索中次数较多,...