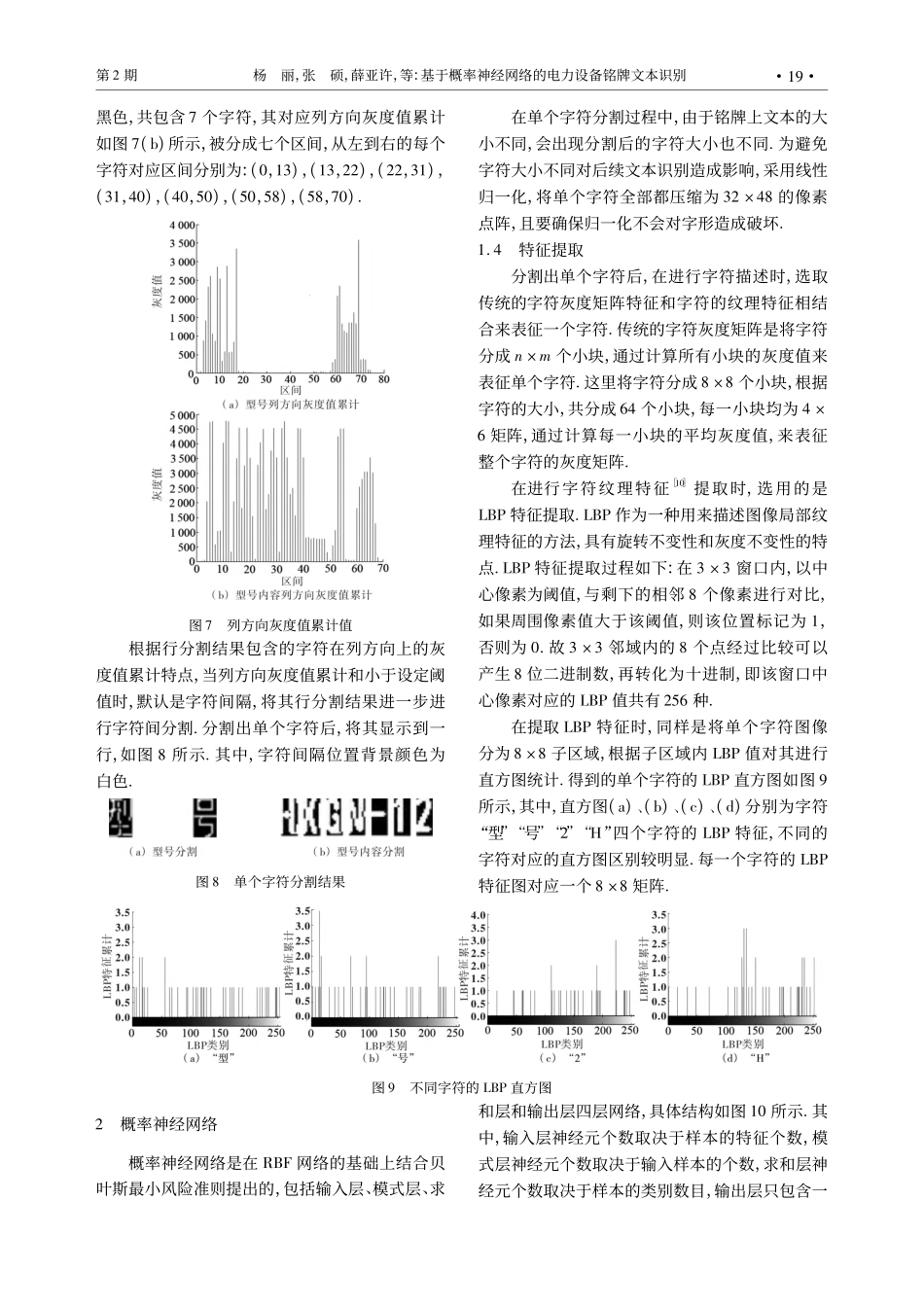
收稿日期:2022-08-29基金项目:平顶山学院青年基金(PXY-QNJJ-2019007)作者简介:杨丽(1987—),女,河南省驻马店市人,工学硕士,平顶山学院电气与机械工程学院实验师,主要从事智能控制研究.基于概率神经网络的电力设备铭牌文本识别杨丽,张硕,薛亚许,杨光(平顶山学院电气与机械工程学院,河南平顶山467036)摘要:针对电力设备入库统计管理存在的问题,提出一种基于概率神经网络的电力设备铭牌文本识别方法.根据Prewitt边缘检测算子、逻辑运算、文本列方向灰度值累计值,实现铭牌文本的字符分割;利用字符灰度矩阵和LBP直方图统计,对字符进行多特征综合提取;设计概率神经网络(PNN)模型,对分割后的字符图像进行批量训练和测试,并与RBF网络模型作对比.结果表明:当扩散速度Spread取0.1时,加噪、不加噪图像训练的结果均为最优;PNN模型在训练时间、正确率方面均具有较明显的优势.关键词:电力设备;文本识别;字符分割;概率神经网络中图分类号:TP391.413文献标识码:A文章编号:1673-1670(2023)02-0017-050引言用电规模的扩张及用电结构的多元化导致越来越多的电力设备投入生产运行[1-2],电力设备的验收、入库、维护、检修等管理工作变得越来越复杂.通常是采用现场读取或拍照记录设备铭牌的相关参数,再通过办公软件绘制表格,工作效率较低,同时需要较多人力.对于一些电压等级高、辐射量大等工作环境较为复杂的场合,现场记录铭牌参数的风险大大提高.铭牌参数的自动识别已经变得越来越重要,铭牌参数通常是由数字、中英文字符、特殊字符等文本组成.文献[3-4]根据电力设备铭牌文本的特点,将文本分为可变区域和不可变区域,对于可变区域,采用Keras深度学习理论搭建残差网络模型,识别率高达98%,但是仅限于已知类别的电气铭牌;对于不可变区域,采用建立模板数据库进行分类识别,但是同样仅限于已知类别的电气铭牌.文献[5]将文本看作一个序列,同样是利用深度学习方法对文本进行端到端识别[6],可以根据铭牌文本的定位获取设备参数,但是当出现大量字母和特殊字符或多行文本时,识别效果不够理想.文献[7]利用支持向量机对提取的字符的小波能量和边缘方向直方图的特征进行最优排列,达到识别目的,但是对于特殊字符的识别没有提及.也有文献利用形状上下文[8-9]算法来描述字符特征,并取得较好效果.针对现有电力设备铭牌文本识别研究存在的问题,提出一种基于概率神经网络的电力设备铭牌文本识别方法.首先获得电力设...