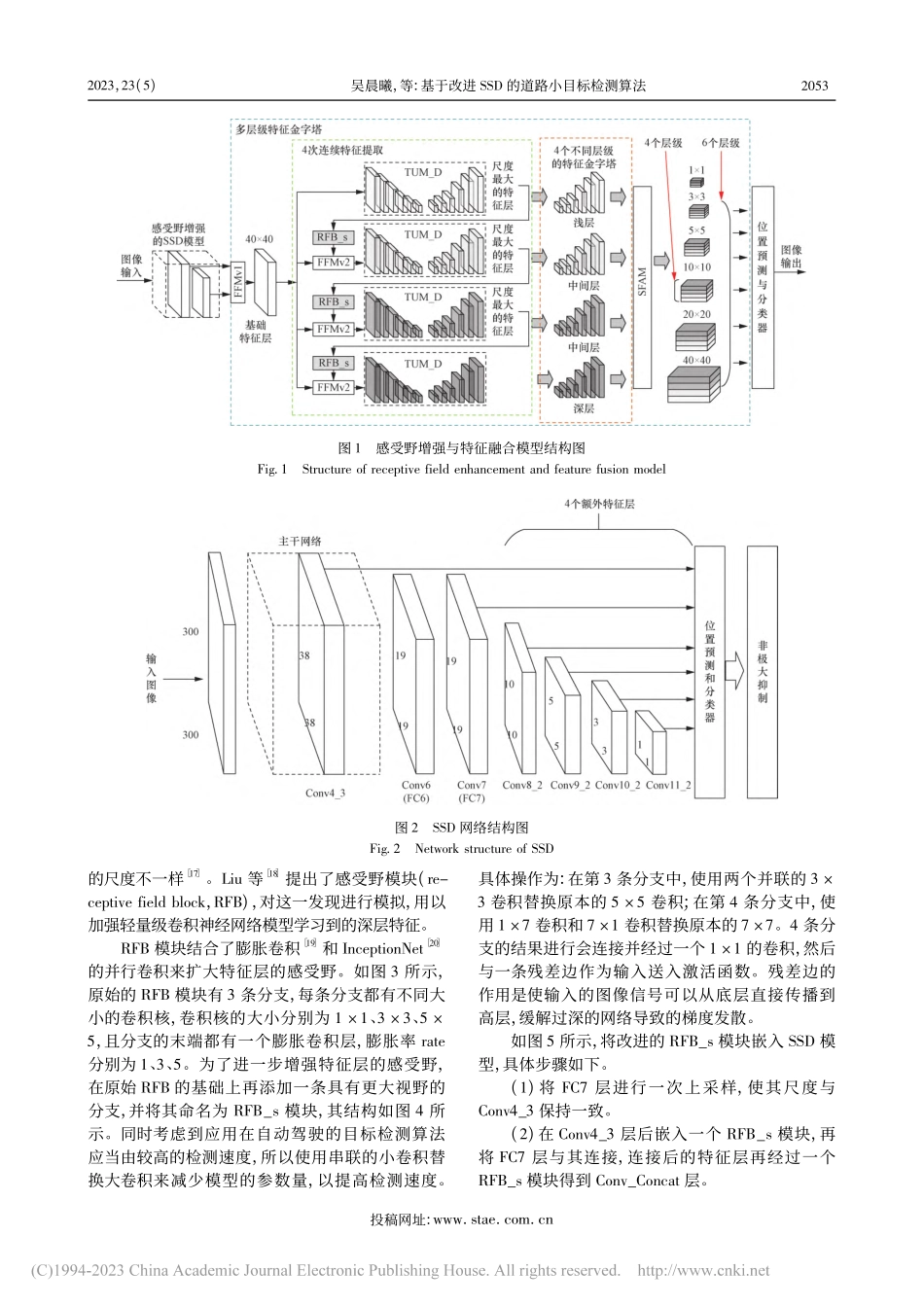
投稿网址:www.stae.com.cn2023年第23卷第5期2023,23(5):02051-08科学技术与工程ScienceTechnologyandEngineeringISSN1671—1815CN11—4688/T收稿日期:2022-05-26;修订日期:2022-11-14基金项目:湖北省重点研发计划(2021BAA180)第一作者:吴晨曦(1997—),男,汉族,湖北武汉人,硕士研究生。研究方向:图像处理。E-mail:wuchenxi@wust.edu.cn。*通信作者:许小伟(1983—),男,汉族,湖北武汉人,博士,副教授。研究方向:智能网联汽车技术。E-mail:xuxiaowei@wust.edu.cn。引用格式:吴晨曦,应保胜,许小伟,等.基于改进单步多框目标检测的道路小目标检测算法[J].科学技术与工程,2023,23(5):2051-2058.WuChenxi,YingBaosheng,XuXiaowei,etal.Roadsmalltargetdetectionalgorithmbasedonimprovedsingleshotmultiboxdetector[J].ScienceTechnologyandEngineering,2023,23(5):2051-2058.基于改进单步多框目标检测的道路小目标检测算法吴晨曦1,应保胜1,许小伟1*,刘光华2,程书瑾1(1.武汉科技大学汽车与交通工程学院,武汉430065;2.智新科技股份有限公司,武汉430058)摘要针对单步多框目标检测(singleshotmultiboxdetector,SSD)算法运用于自动驾驶领域时,在检测道路上小目标容易发生漏检错检的情况,提出一种改进的SSD目标检测算法。该算法首先在SSD模型的主干网络中嵌入感受野增强模块,扩大特征层的感受野,以获取更多小目标的特征信息;其次,在主干网络后加入4次U形特征提取结构,构建4个不同层级的特征金字塔;最后,合并成一个多层级特征金字塔用于检测。结果表明,该改进SSD模型在KITTI数据集上的检测精度较原始SSD模型提升了6%,检测速度达到27.9帧/s。在兼顾检测效率的同时,有效提高了对道路上小目标的检测精度,更适用于自动驾驶领域。关键词感受野;目标检测;多层级特征融合;SSD中图法分类号TP391.4;文献标志码ARoadSmallTargetDetectionAlgorithmBasedonImprovedSingleShotMultiboxDetectorWUChen-xi1,YINGBao-sheng1,XUXiao-wei1*,LIUGuang-hua2,CHENGShu-jin1(1.CollegeofAutomobileandTrafficEngineering,WuhanUniversityofScienceandTechnology,Wuhan430065,China;2.IntelligentPowerSystemCo.,Ltd.,Wuhan430058,China)[Abstract]Aimingatthesituationthatthesingleshotmultiboxdetector(SSD)targetdetectionalgorithmispronetomissdetectionandwrongdetectionwhendetectingsmalltargetsont...