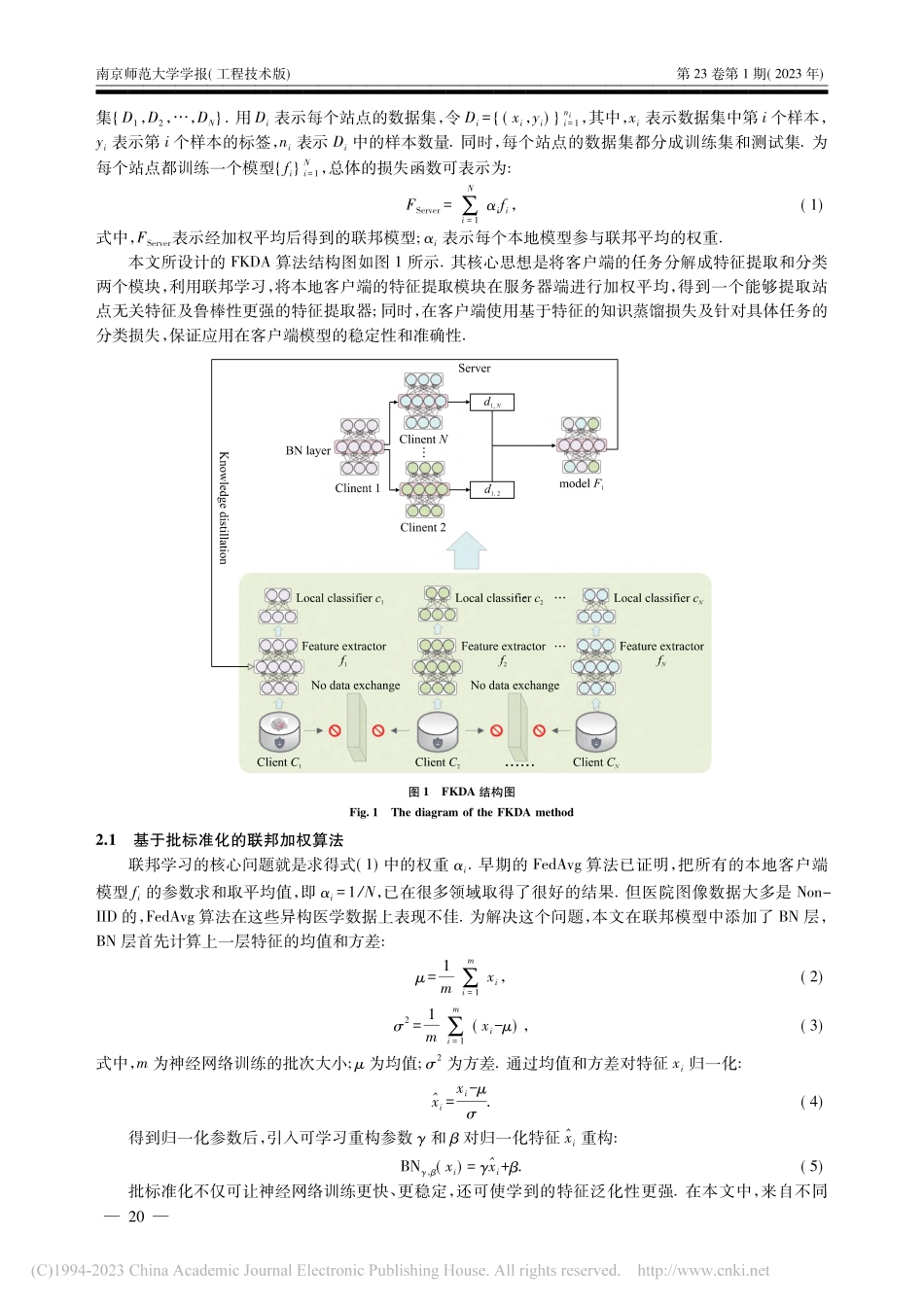
第23卷第1期2023年3月南京师范大学学报(工程技术版)JOURNALOFNANJINGNORMALUNIVERSITY(ENGINEERINGANDTECHNOLOGYEDITION)Vol.23No.1Mar,2023收稿日期:2022-09-15.通讯作者:朱旗,博士,副教授,研究方向:机器学习、模式识别、脑疾病诊断.E-mail:zhuqinuaa@163.comdoi:10.3969/j.issn.1672-1292.2023.01.003基于联邦知识蒸馏的多站点脑疾病诊断方法杨启鸣1,朱旗1,王明明1,孙凯2,朱敏3,邵伟1,张道强1(1.南京航空航天大学计算机科学与技术学院,江苏南京211106)(2.深圳市华赛睿飞智能科技有限公司,广东深圳518063)(3.南京航空航天大学公共实验教学部,江苏南京211106)[摘要]多中心疾病诊断方法通过整合不同医疗机构的样本信息到一台服务器上,集中训练来提高预测的准确性,有效解决了医疗领域小样本的问题.但仍存在两个问题:不同医疗机构的数据分布不同以及无法保护病人的隐私.基于此,设计了一种应用在多站点脑疾病诊断领域中隐私保护的联邦知识蒸馏算法.首先,设计了服务器端基于批标准化的加权平均算法,帮助联邦模型提取各个医疗机构数据分布无关的特征.之后,在客户端设计了联邦教师模型-本地学生模型的框架,部署了本地分类器,利用蒸馏损失保证模型提取本地化特征,利用分类损失保证模型性能稳定.实验结果表明,该算法在自闭症及精神分裂症数据集上均优于现有的其他算法.[关键词]联邦学习,知识蒸馏,脑疾病诊断[中图分类号]TP391[文献标志码]A[文章编号]1672-1292(2023)01-0018-07Multi-SiteBrainDiseaseDiagnosisMethodBasedonFederalKnowledgeDistillationYangQiming1,ZhuQi1,WangMingming1,SunKai2,ZhuMin3,ShaoWei1,ZhangDaoqiang1(1.CollegeofComputerScienceandTechnology,NanjingUniversityofAeronauticsandAstronautics,Nanjing211106,China)(2.ShenzhenHuasaiRuifeiIntelligentTechnologyCo.,Ltd.,Shenzhen518063,China)(3.PublicExperimentalTeachingDepartment,NanjingUniversityofAeronauticsandAstronautics,Nanjing211106,China)Abstract:Themulti-sitediseasediagnosismethodcanimprovetheaccuracyofpredictionbyintegratingthesampleinformationofdifferentmedicalinstitutionsintooneserver,whicheffectivelysolvestheproblemofsmallsamplesizeinthemedicalfield.However,mostoftheseapproacheshavetwoproblemsinthemedicalfieldwhichbeingthediffe...