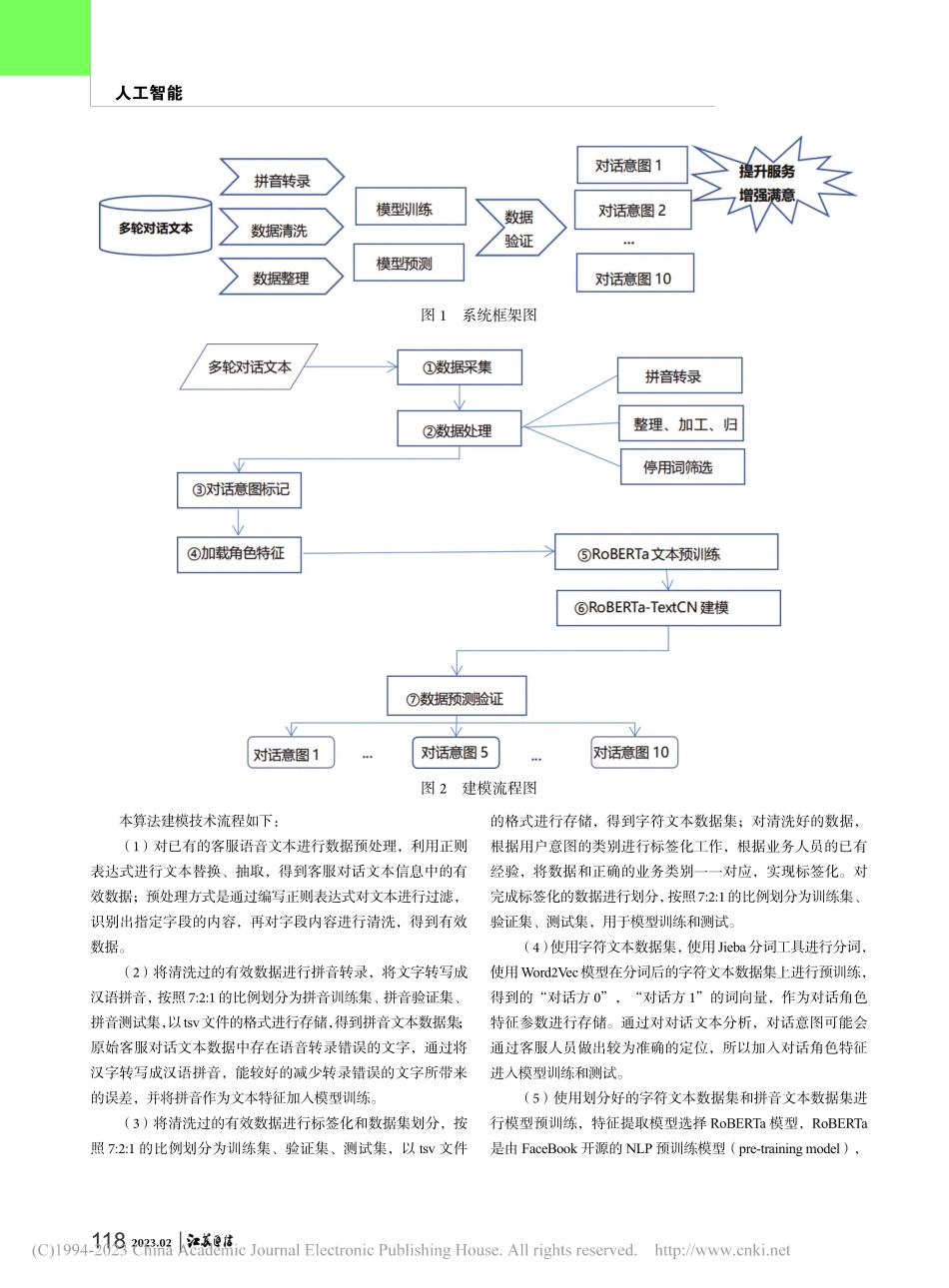
1172023.02人工智能0引言运营商在为客户服务过程中,外呼人员和客户在多轮对话场景下电话语音内容包含很多用户需求和感受方面的信息,充分了解用户的真实感受可以更深入全面地服务好客户,因此,在客服语音多轮对话场景下对语音转录文本进行用户意图和需求识别,提供客服实时辅助、AI智能服务质检、FAQ知识图谱应用等高端服务能力,可以快速精准地提供高质量客户服务。本文介绍一种基于深度学习算法的多轮对话意图识别全流程创新应用,具备高精度的意图识别准确率,可以为客户提供更多的精准服务,提升服务质量,增强客户满意度。1意图识别技术路线用户意图识别的任务可以抽象为自然语言处理中的文本分类任务,可以使用相关算法实现自动意图识别代替人工识别操作。文本分类是指对给定的非结构化文本,根据相应的分类算法或模型,得到文本对应的类别,用于相关判断。传统的机器学习算法基于人工特征工程提取文本特征,在文本分类上的准确率和鲁棒性上都存在一定局限。基于传统循环神经网络和卷积神经网络的深度学习算法对于训练数据的质量要求较高,需要研究选择一种更加准确有效的分类算法,用于实现用户意图分类识别。本文介绍的意图识别技术基于深度学习及预训练语言模型,通过纯半监督学习构建携带用户意图标注的语音转写文本,采用Soft-maskedBERT模型和开源语料进行文本纠错,构建待识别语料的对话角色信息特征和拼音信息特征,利用嵌入方式将对话角色和汉字拼音映射为高维稠密向量,通过训练基于RoBERTa预训练模型的意图识别模型,预测语音对话文本所属用户意图类别并作为意图识别结果输出。节省了大量以往意图识别任务中大量的人工标注成本,独创性地引入角色信息特征和拼音信息特征,降低了语音转录带来的噪声,通过深度学习模型算法的创新性组合应用,实现了高精度的多轮对话场景下的对话意图识别准确率,在各行业客服质量提升和对话意图识别方面有着较为广泛的应用前景。2技术方案对话意图进行识别所使用的数据源主要由对话文本组成。将原有的业务系统中相关数据进行抽取、清洗、加工、整理、加载到数据仓库中,在数据仓库中形成基础的分析数据的存储。如图1所示。运用Roberta-CNN对对话文本进行自然语言处理分析,建模预测分析提供实时应用和进一步的业务模型分析应用。建模流程如图2所示。3建模流程基于深度学习的多轮对话意图识别技术在运营商的应用实践唐维东中国电信股份有限公司南京分公司摘要:本文介绍一种基于深度学习算法的运...