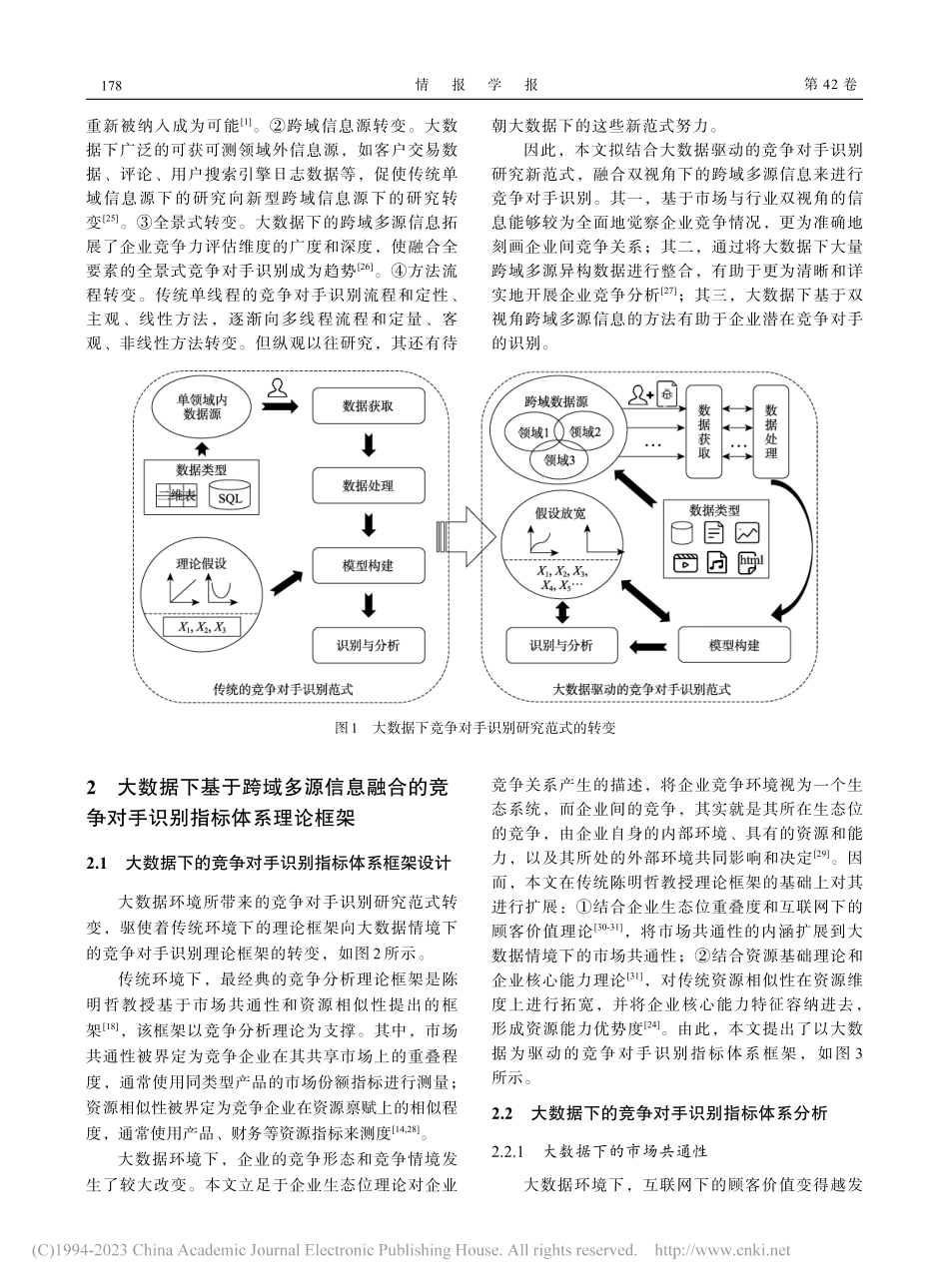
情报学报2023年2月第42卷第2期JournaloftheChinaSocietyforScientificandTechnicalInformation,Feb.2023,42(2):176-188大数据下基于跨域多源信息融合的竞争对手识别模型研究——基于新能源汽车行业宋新平,陈梦梦,吕国栋,申彦(江苏大学管理学院,镇江212013)摘要大数据下竞争对手识别模式发生了显著转变,催生了新型竞争对手识别研究范式。本文以该新范式为导向,借鉴企业生态位理论与互联网下的顾客价值理论,对传统经典陈明哲竞争分析框架进行拓展,提出了基于大数据下的市场共通性和资源能力优势度的竞争对手识别指标体系框架。该框架整合了行业与市场双元视角下的财务、专利、产品、客户等多方跨域信息源,使用模糊C均值聚类构建模型,并以新能源汽车行业为例开展仿真实验研究。结果表明,基于跨域多源信息融合的模型可有效提高竞争对手识别的准确性和全面性。关键词大数据;竞争对手;多源信息融合;综合视角;模糊C均值聚类AResearchonCompetitorIdentificationModelBasedonCross-domainandMulti-sourceInformationFusionintheContextofBigData—BasedontheNewEnergyAutomobileIndustrySongXinping,ChenMengmeng,LyuGuodongandShenYan(SchoolofManagement,JiangsuUniversity,Zhenjiang212013)Abstract:Therehavebeensignificantchangesinthepatternofcompetitoridentificationunderthebigdataenvironment,engenderinganewresearchparadigmofcompetitoridentification.Guidedbythenewparadigm,thisarticlemodifiesthetraditionalclassiccompetitiveanalysisframeworkofChenMing-Jer,andthenpresentsanewcompetitoridentificationin‐dexsystemframeworkconsistingofmarketcommonalityandresourcecapabilityadvantage,usingthetheoryofcorporateniche,theviewofresourcesandability,andthetheoryofcustomervalue.Theframeworkintegratescross-domainandmulti-sourceinformationsourcessuchasfinance,patents,products,andcustomersfromtheperspectiveoftheindustryandmarket.Subsequently,thecompetitoridentificationmodelisbuiltbasedonthefuzzyC-meansclusteringalgorithm,andthenewenergyautomobileindustryistakenasanexampletocarryoutsimulationexperiments.Theresultsshowthatthemodelcaneffectivelyimprovetheaccuracyandcomprehensivenessofcompetitoridentification.Keywords:bigdata;competitors;multi-sourceinformationfusi...