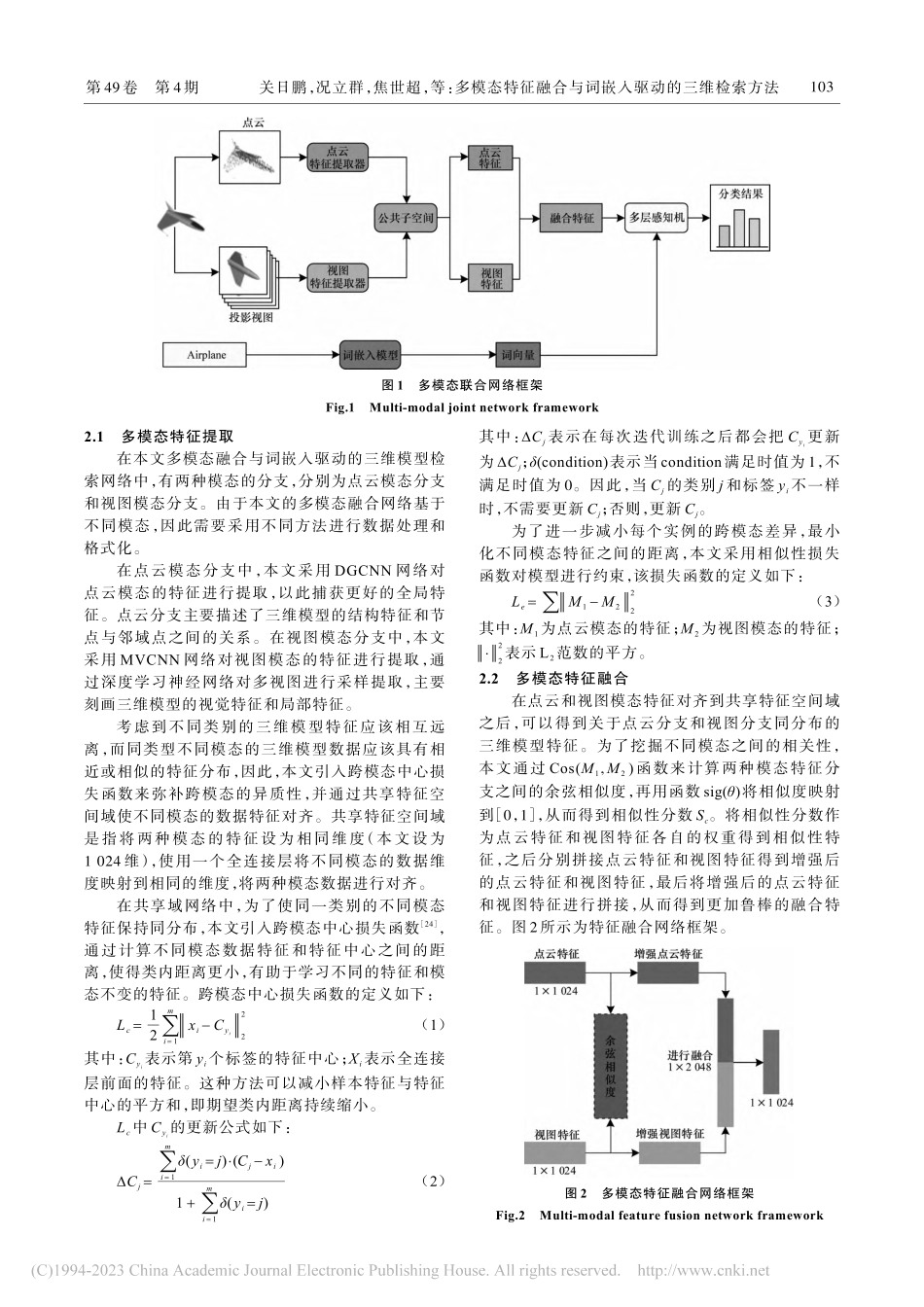
第49卷第4期2023年4月ComputerEngineering计算机工程多模态特征融合与词嵌入驱动的三维检索方法关日鹏,况立群,焦世超,熊风光,韩燮(中北大学大数据学院,太原030051)摘要:在基于点云和图像的三维模型分类检索中,现有特征融合方法忽略了模态内的特征信息和模态间的互补信息,存在融合特征丢失的问题,且分类标签和预测特征之间缺乏高维相关性,检索准确率较低。针对该问题,提出一种多模态特征和词嵌入联合驱动的网络结构,以对三维模型进行分类检索。在特征提取过程中,利用特征提取器提取来自点云和视图的三维模型特征,通过共享空间来对齐不同模态的特征。在模态融合过程中,计算不同模态之间的余弦相似度以增强模态特征,将增强特征进行拼接得到融合特征。在模型特征分类的过程中,通过建立词嵌入模型与分类标签的高维相关性实现三维模型特征的统一表示和分类检索。在ModelNet10和ModelNet40数据集上进行实验,结果表明,该网络的平均检索精度均值分别达到92.9%和91.5%,可以获取精准的三维模型特征描述符,与VoxNet、SCIF、MVCNN等检索方法相比,其能显著提高三维模型的检索精度和分类准确率。关键词:三维模型;特征融合;词嵌入;深度学习;特征提取开放科学(资源服务)标志码(OSID):源代码链接:https://github.com/sikaozhifu/PV_word_embedding_pytorch.git中文引用格式:关日鹏,况立群,焦世超,等.多模态特征融合与词嵌入驱动的三维检索方法[J].计算机工程,2023,49(4):101-107,113英文引用格式:GUANRP,KUANGLQ,JIAOSC,etal.Retrievalmethodof3Dmodelsdrivenbymulti-modalfeaturefusionandwordembedding[J].ComputerEngineering,2023,49(4):101-107,113.RetrievalMethodof3DModelsDrivenbyMulti-modalFeatureFusionandWordEmbeddingGUANRipeng,KUANGLiqun,JIAOShichao,XIONGFengguang,HANXie(SchoolofDataScienceandTechnology,NorthUniversityofChina,Taiyuan030051,China)【Abstract】In3Dmodelclassificationandretrievalbasedonpointcloudsandimages,theexistingfeaturefusionmethodsdonotconsiderthefeatureinformationinthemodeandthecomplementaryinformationbetweenmodes.Additionally,fusionfeaturelossoccurs,nohigh-dimensionalcorrelationisindicatedbetweenclassificationlabelsandpredictionfeatures,andtheretrievalaccuracyislow.Hence,anetworkstructuredrivenbymulti-...