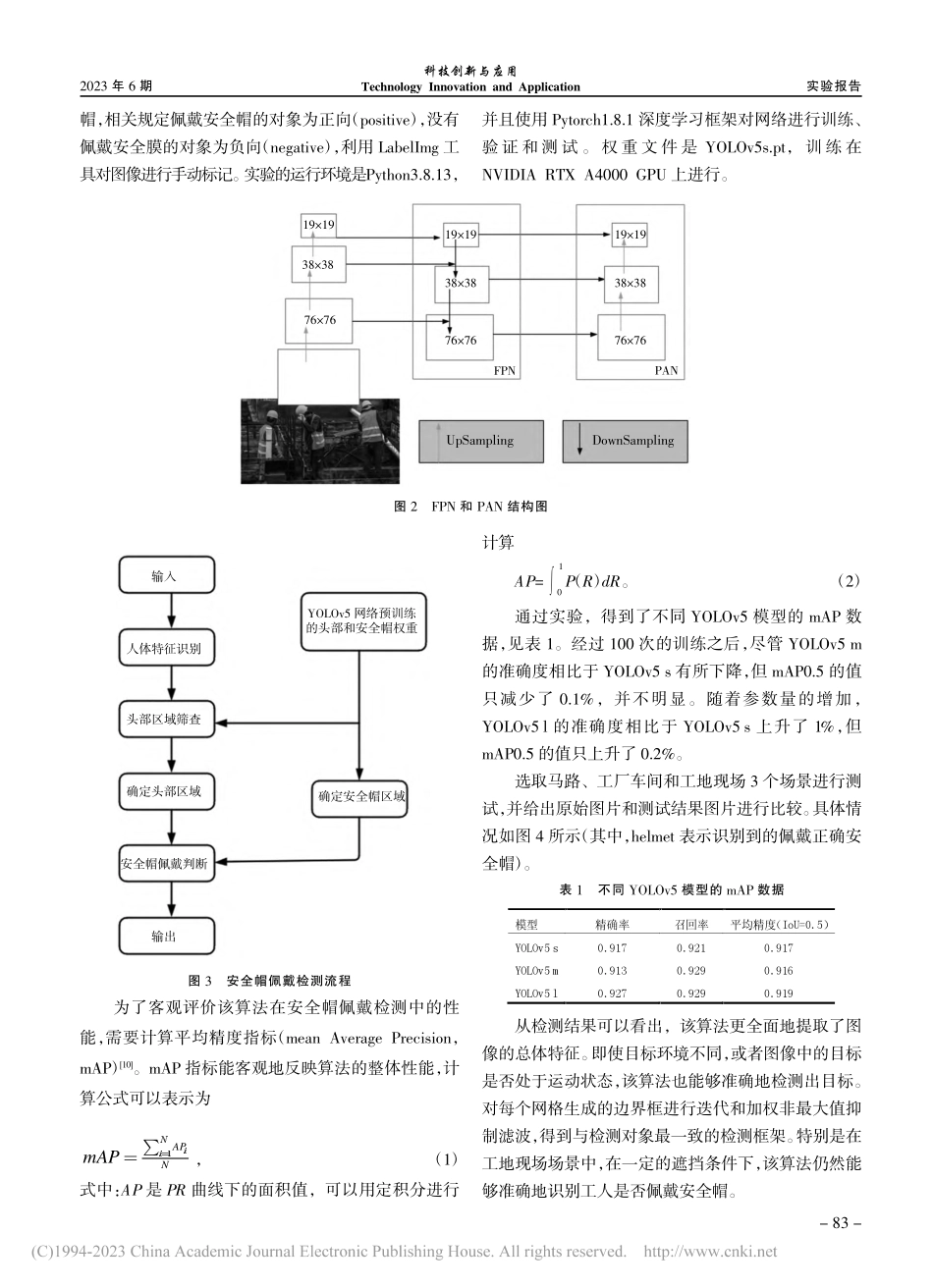
实验报告科技创新与应用TechnologyInnovationandApplication2023年6期基于改进YOLOv5的安全帽检测算法梁循1,翁小林1,李嘉伟1,刘倩2,3,4(1.重庆市建设工程施工安全管理总站,重庆400010;2.重庆邮电大学通信与信息工程学院,重庆400065;3.移动通信技术教育部重点实验室,重庆400065;4.移动通信技术重庆市重点实验室,重庆400065)安全帽作为劳动者最基本的个人防护装备,对保护劳动者的生命安全具有重要意义。但是,由于缺乏安全观念,一些工人经常不戴安全帽上班。通过图像和视频进行安全帽的检测已经成为生产安全监测的重要手段[1],特别是在建筑工地这具有一定危险性的作业场所。在传统的头盔佩戴检测方法中,大多数检测工作是基于人工设置的特征,但在实际应用中由于光源或角度问题使得目标与背景的区别不是很明显,特征提取工作极为烦琐。随着深度学习技术的发展,特别是卷积神经网络[2]的出现,该模型的图像特征提取能力得到了很大的提高。另外,支持向量机等分类器[3]可以对提取的图像特征进行分类和预测,有效地降低了特征选择的难度。目前,目标检测的主流算法是R-CNN[4]系列和YOLO[5]系列。但R-CNN系列算法是两阶段检测算法,将耗费大量时间,即使是更快的R-CNN算法。YOLO系列算法已经开发到YOLOv5[6],已经是一级检测算法,可以一步完成R-CNN系列算法检测过程,检测速度能够满足实时性要求。针对安全帽检测的研究已经引起了众多学者的关注。Wen等[7]提出了一种基于改进Hough变换的圆弧/弧检测方法,并将其应用于ATM监控系统中的安全帽检测。Rubaiyat等[6]结合颜色特征提取技术和循环Hough变换特征提取技术,对建筑工人头盔使用情况进行检测。Kang等[8]采用了ViBe背景建模算法,利用实时人体分类框架对变电站内的行人进行准确、快速摘要:安全帽作为劳动者最基本的保护,对劳动者的生命安全具有重要意义。但是,由于缺乏安全意识,在建筑工地中存在安全帽佩戴不规范的情况。随着目标检测技术的不断发展,高精度、高效率的YOLO系列算法已经被应用于各种场景检测任务中。为建立起数字化的安全帽监测系统,该文首先对建筑工地中安全帽佩戴情况所采集的7581张图片进行标注。然后,提出一种基于改进的YOLOv5的安全帽检测方法,并使用不同参数的YOLOv5(s,m,l)模型进行训练和测试,对这3种模型进行比较和分析。使用可训练目标探测器YOLOv5s的mAP达到91.7%,证明基于改进的YOLOv5的头盔探测的有效性。关键词:安全帽;建筑工地;安全...