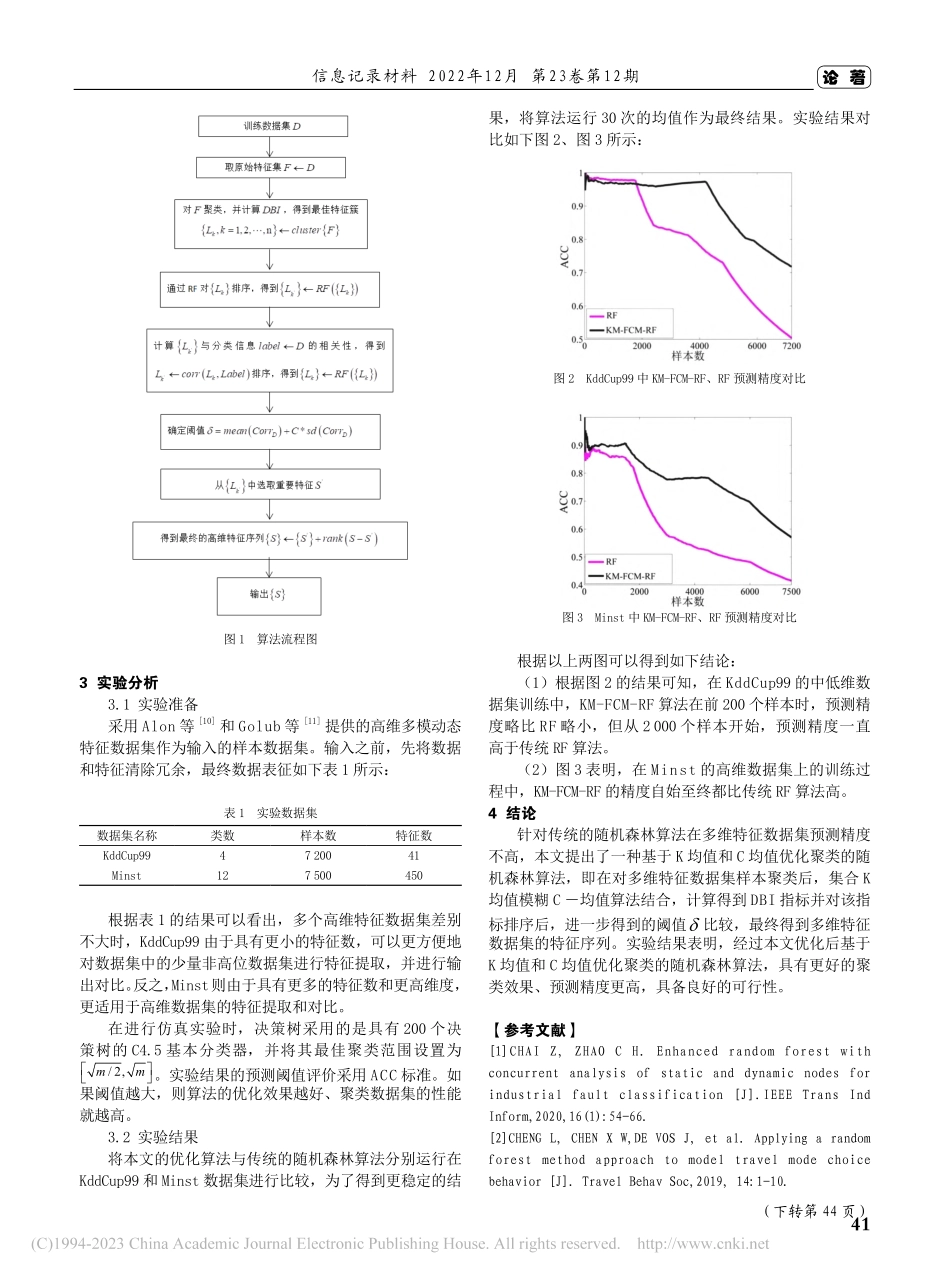
信息记录材料2022年12月第23卷第12期39论著0引言在常用的决策树算法中,最常见的算法是随机森林算法。随机森林算法的优点在于通过对数据噪声的高度容忍度来得到较高预测精确度。Chai[1]将随机森林算法运用到化工故障分类,提高了故障检测精度;Cheng[2]在网络安全方面运用随机森林算法,极大提升了网络安全监测正确率;Zafari[3]在化工项目评估管理领域运用随机森林算法,得到了更加准确的评估预测结果。在具有明显优点的同时,随机森林算法也存在一些缺点,例如对数据集的特点相近似聚类的检索效率比较低,对数据集的动态聚类数据泛化特征时造成的误差估值往往比较大。针对这些缺陷,也有很多学者做了大量的研究以改进。王德军等[4]、刘曙光等[5]、王磊[6]分别采用时间序列特征泛化聚类、遥感数据多时相动态聚类、加权平均泛化数据后聚类的方法,得到了对精度不同程度的提高,并且聚类的效率也得到了相应的改善。对随机森林算法提出了非常有用的改进和补充。本文将尝试采用将特征聚类KM算法与FCM算法相结合,对随机森林算法进行优化,形成KM-FCM-RF算法优化模型。对多模动态K均值聚类和模糊C均值互相融合与补充的方法,采用对多模动态数据集的特征数据进行聚类,对传统的随机森林算法进行优化后,再计算特征优化的差异化DBI的值,重新对DBI序列值进行排序,筛选相关的特征,在聚类多模动态数据时达到提高效率的目的。1传统随机森林算法如果研究人员用Ntree表示决策树中多维特征的数量,OOBi表示第i棵决策树的多模动态数据的特征数据,ErrOOBi代表的是OOBi中错误数据样本的数量,如果有一个数据集的特征有d个,那么这个数据集可以称之为数据集D,XJ(j=1,2,…,d)表示该数据特征集的度量,其算法步骤如下:步骤1:首先基础得到多雾的样本数量ErrOOBi的值;步骤2:置换后,得到了XJ,再次置换后得到OOBi——;步骤3:均值计算OOBi——得到的值,可以表示为jiErrOOB;步骤4:重复以上步骤1到步骤3,执行次数限定为Ntree次,循环结束后可以得到{ErrOOBi,i=1,2,L,Ntree}和{},1,2,,jitreeErrOOBiN=L步骤5:根据以上两个输出结果,可计算粗聚类变化的均值:(){}1JjiiitreeVIXErrOOBErrOOBN=−∑(1)基于特征聚类优化的KM-FCM-RF算法研究罗超,彭玉涛(井冈山大学网络信息中心江西吉安343009)【摘要】针对传统的随机森林算法(RF)在对聚类效率欠佳导致训练精度不高的缺陷,本文提出了一种基于特征聚类的随机森林算法(KM-FCM-RF),首先用传统RF方...