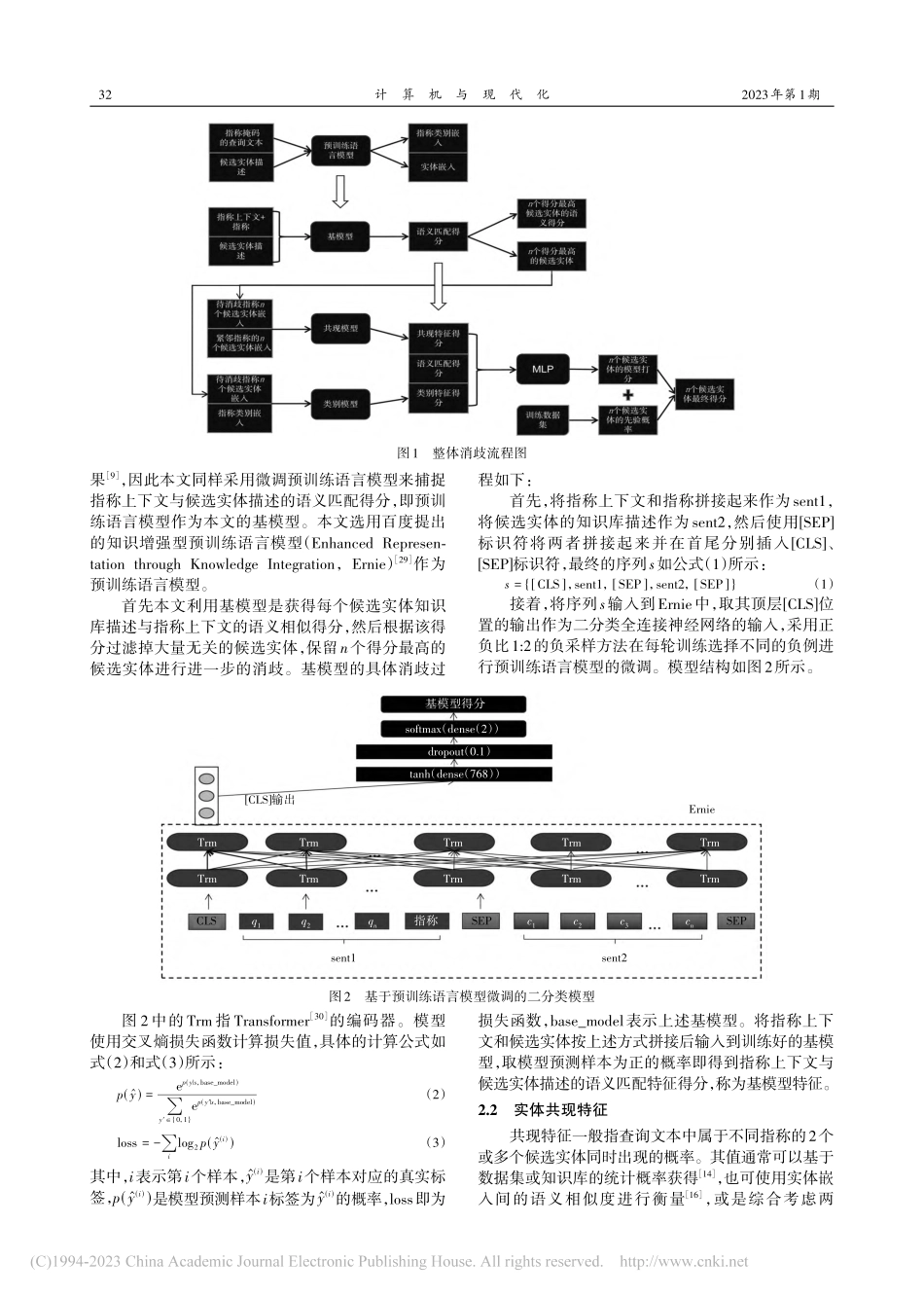
计算机与现代化JISUANJIYUXIANDAIHUA2023年第1期总第329期0引言近年来,中文短文本实体消歧成为自然语言处理(NaturalLanguageProcessing,NLP)领域中众多下游任务的基础工作,如基于搜索引擎的实体搜索任务[1]、基于知识库的问答任务[2]、知识图谱构建[3]等,并且起到了越来越重要的作用。实体消歧是指将一段文本中指定的指称映射到知识库中某个实体的过程,其难点主要在于知识库中一般存在多个与指称同名的实体且每个实体又存在多种表示方式。长文本具有丰富的上下文语境和充足的语义信息,有利于长文的实体消歧。然而像查询文本、微博评论以及其他更短的文本,由于上下文语境不够充分、语义稀疏、文本口语化等问题,仅凭指称上下文与候选实体描述的语义相似度来对指称进行消歧,往往难以取得较好的效果[4]。针对基于短文本实体消歧存在的上述问题,本文提出一种基于多特征因子融合的实体消歧模型,通过使用多层感知机(MultilayerPerceptron,MLP)和加权融合,将候选实体在不同角度的特征得分进行融合,综合考虑指称上下文与候选实体描述的语义相似度、指称类别嵌入与实体嵌入的语义相似度、同一查询文本中相邻指称候选实体间的共现关系,以及实体流行度4个特征,来更好地完成中文短文本的实体消歧。1相关工作1.1中英文长文本消歧模型早期的实体消歧大多是在中英文的长文本数据集上进行的,并且按照消歧对象的不同可分为局部消歧模型和全局消歧模型。局部消歧模型[5-9]对文档中的每个指称单独消歧,一般基于词向量和循环神经网基于多特征因子融合的中文短文本实体消歧王永缔,雷刚(江西师范大学软件学院,江西南昌330022)摘要:现有中文短文本实体消歧模型在消歧过程中大多只考虑指称上下文与候选实体描述的语义匹配特征,对同一查询文本中候选实体间的共现特征以及候选实体与实体指称类别相似特征等有效的消歧特征考虑不足。针对这些问题,本文首先利用预训练语言模型获得指称上下文与候选实体描述的语义匹配特征;然后,针对实体嵌入和指称类别嵌入提出共现特征与类别特征;最后,通过融合上述特征实现基于多特征因子融合实体消歧模型。实验结果表明本文提出的共现特征及类别特征在实现实体消歧中的可行性和有效性,以及本文提出的基于多特征因子融合的实体消歧方法能够取得更好的消歧效果。关键词:共现特征;类别特征;多特征因子;多头注意力;Ernie中图分类号:TP391文献标志码:ADOI:10.3969/j.issn.1006-2475.2023.01.00...