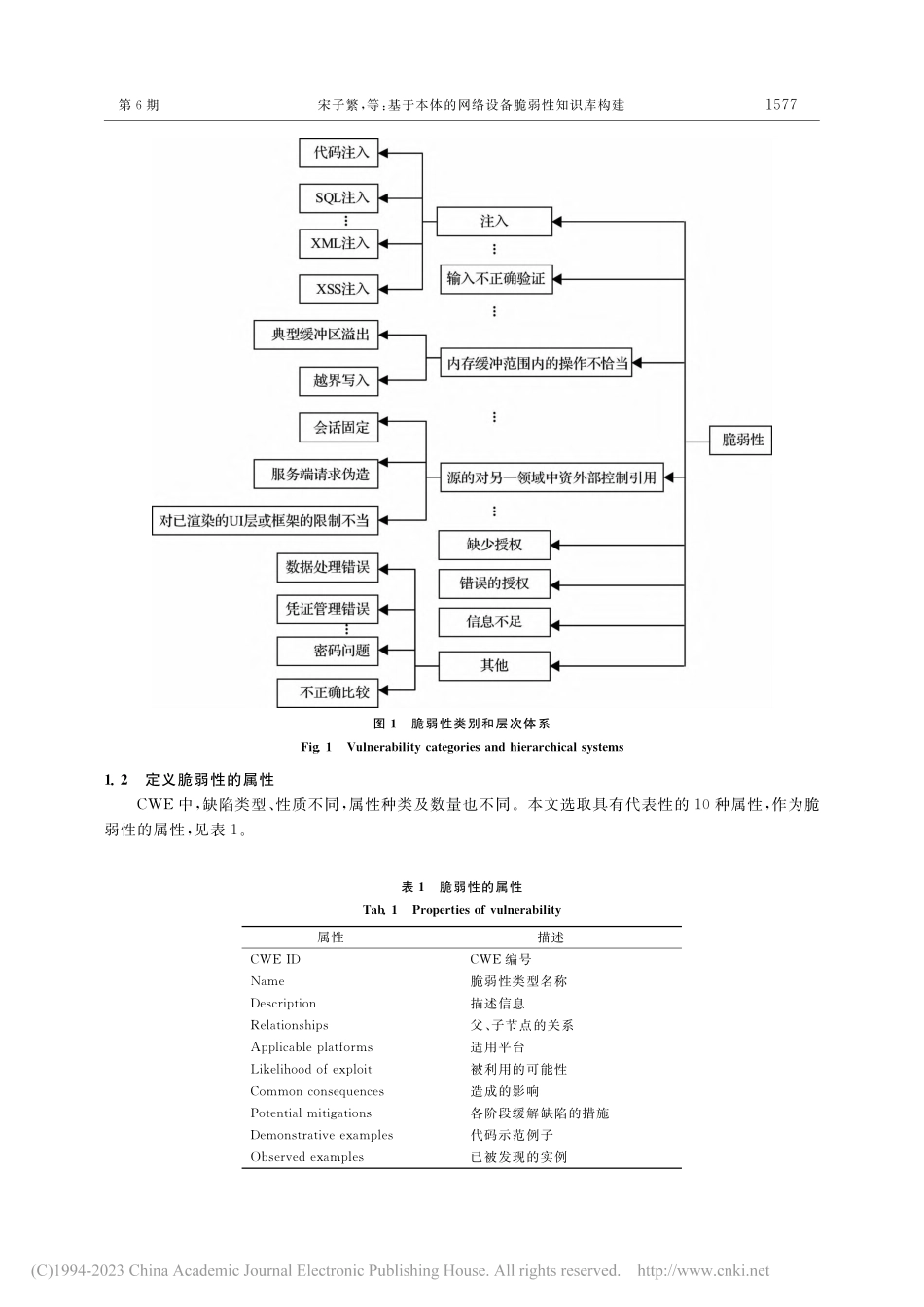
第47卷第6期2022年12月广西大学学报(自然科学版)JournalofGuangxiUniversity(NaturalScienceEdition)Vol.47No.6Dec.2022收稿日期:2021-05-17;修订日期:2022-08-11基金资助:国家自然科学基金项目(61962020);江西省主要学科学术和技术带头人资助计划项目(20172BCB22015)通讯作者:肖美华(1967—),男,华东交通大学教授,博士生导师,博士;E-mail:xiaomh@ecjtu.edu.cn。引文格式:宋子繁,肖美华,钟逸洲,等.基于本体的网络设备脆弱性知识库构建[J].广西大学学报(自然科学版),2022,47(6):1575-1584.DOI:10.13624/j.cnki.issn.1001-7445.2022.1575基于本体的网络设备脆弱性知识库构建宋子繁,肖美华*,钟逸洲,罗敏(华东交通大学软件学院,江西南昌330013)摘要:针对网络设备脆弱性分析与预测,提出一种基于本体的网络设备脆弱性知识库构建方法。该方法将知识库构建分为3个部分:基于通用缺陷列表(CWE)构建网络设备脆弱性本体,形成脆弱性领域语义知识;为解决网络设备脆弱性数据获取难度大的问题,设计开发并发爬虫工具,高效构建网络设备脆弱性数据库;为提升关联规则挖掘效果,借助脆弱性领域语义知识,将构建的脆弱性数据库中、低层级脆弱性提升为高层级脆弱性,提高项集支持度,采用Apriori算法挖掘网络设备和脆弱性之间的关联规则。实验结果表明:构建的网络设备脆弱性知识库中包含更多网络设备和脆弱性关联规则,根据关联规则可对网络设备脆弱性进行有效分析与预测。关键词:网络设备脆弱性;通用缺陷列表;本体;爬虫工具;关联规则挖掘中图分类号:TP311文献标识码:A文章编号:1001-7445(2022)06-1575-10ConstructionofnetworkdevicevulnerabilityknowledgebasebasedonontologytechnologySONGZi-fan,XIAOMei-hua*,ZHONGYi-zhou,LUOMin(SchoolofSoftware,EastChinaJiaotongUniversity,Nanchang330013,China)Abstract:A...