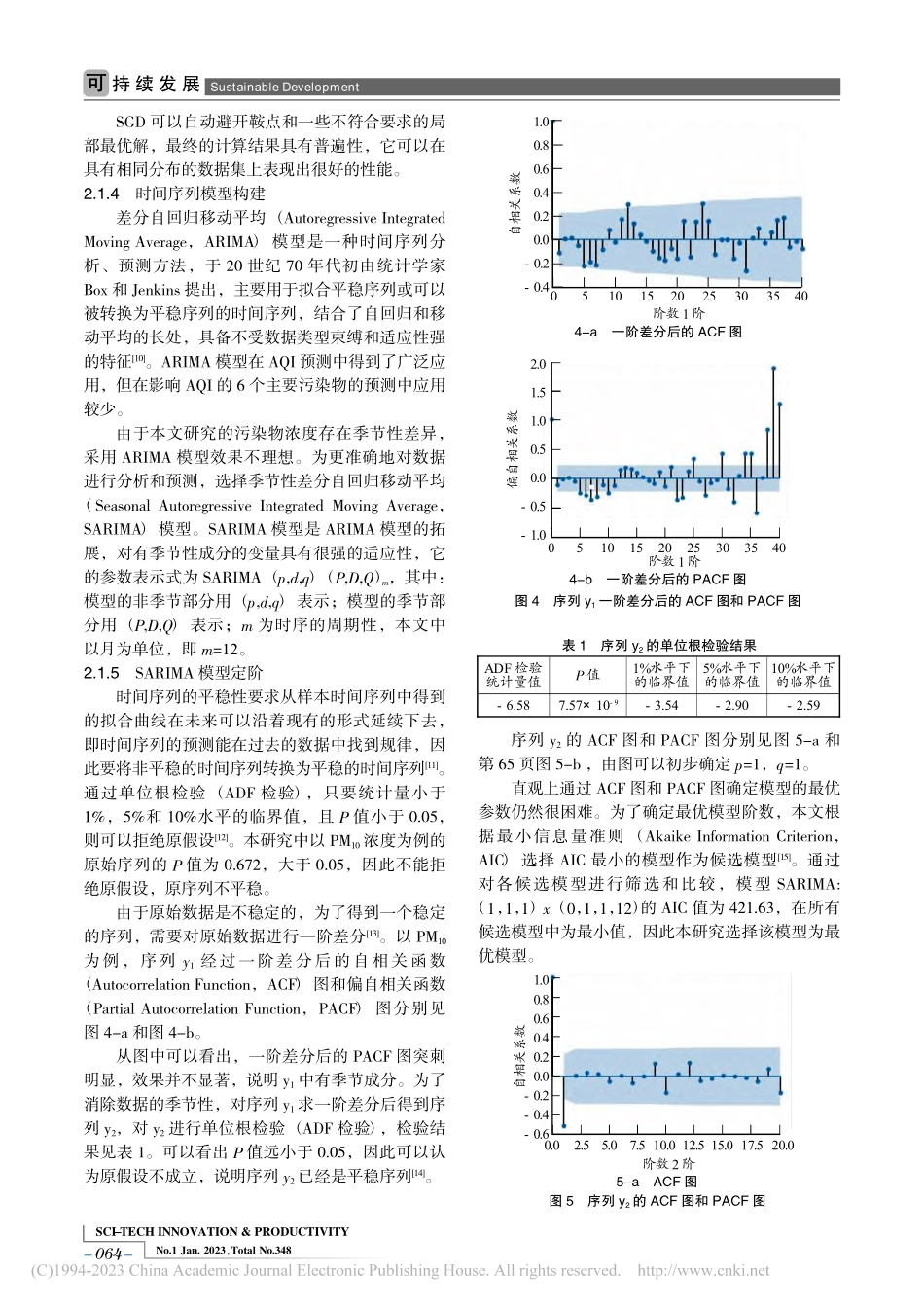
SCI-TECHINNOVATION&PRODUCTIVITYNo.1Jan.2023,TotalNo.348基于MLP和SARIMA的青岛市AQI预报模型收稿日期:2022-04-16;修回日期:2022-06-21作者简介:马风滨(2000—),男,山东滨州人,在读本科,主要从事自动化研究,E-mail:fengbin_ma@163.com。马风滨摘要:为掌握青岛市空气质量变化特征,为空气质量管控提供参考,以2014—2021年青岛市空气质量指数月统计历史数据为基础,通过深度学习算法中的多层神经网络建立了AQI与PM2.5等6个主要污染物的预报模型,对青岛市空气质量的影响因素进行研究,并基于SARIMA模型预测了各污染物的浓度值,结合污染物浓度预测值和预报模型对AQI值进行了预测。根据预测结果,给出了改善青岛市空气质量的建议。关键词:空气质量预报;空气质量指数;污染物;时间序列;多层感知机;SARIMA模型中图分类号:X51;TP183文献标志码:ADOI:10.3969/j.issn.1674-9146.2023.01.062(山东科技大学,山东青岛266590)文章编号:1674-9146(2023)01-062-06随着中国经济的快速发展和城镇化步伐的加快,环境问题日益突出,空气质量问题成为人们关注的焦点。青岛是我国知名旅游城市,空气质量管理是青岛环境保护的重要一环[1]。基于此背景,本文探讨了青岛市空气质量指数(AirQualityIndex,AQI)与各污染物的变化规律,并对青岛市AQI进行了预测。AQI是描述城市环境空气质量综合状况的无量纲指数[2],根据《环境空气质量评价技术规范(试行)》,它综合考虑了SO2、NO2、PM10、PM2.5、CO、O3等污染物的危害程度,AQI值越小,表明空气污染程度越小[3]。建立一个可靠的模型来预测AQI的变化趋势,对防止环境污染和改善空气质量具有重要意义。焦东方和孙志华[4]基于多元回归分析模型,对青岛市空气质量进行了分析和预测。Gogikar等[5]基于多元线性回归估算方法建立了印度阿格拉市和鲁吉拉市的PM2.5预测模型,指出两市的工业发展方向。温情等[6]基于长短期记忆网络实现了对郑州市PM2.5的长期预测。本文基于深度学习网络中的多层感知机(MultilayerPerceptron,MLP)建立青岛市AQI预报模型,通过均方根误差、标准化平均误差、Pearson相关系数等进行模型检验,建立准确可靠的AQI预报模型,为更好地实现青岛市空气质量管控提供参考。1数据来源与处理1.1数据来源本文中的空气质量数据参考了中国空气质量在线监测分析平台(https://www.aqistudy.cn/historydata/)公布的2014—2021年青岛市空气质量月统计历史数据,包括6种主要污...