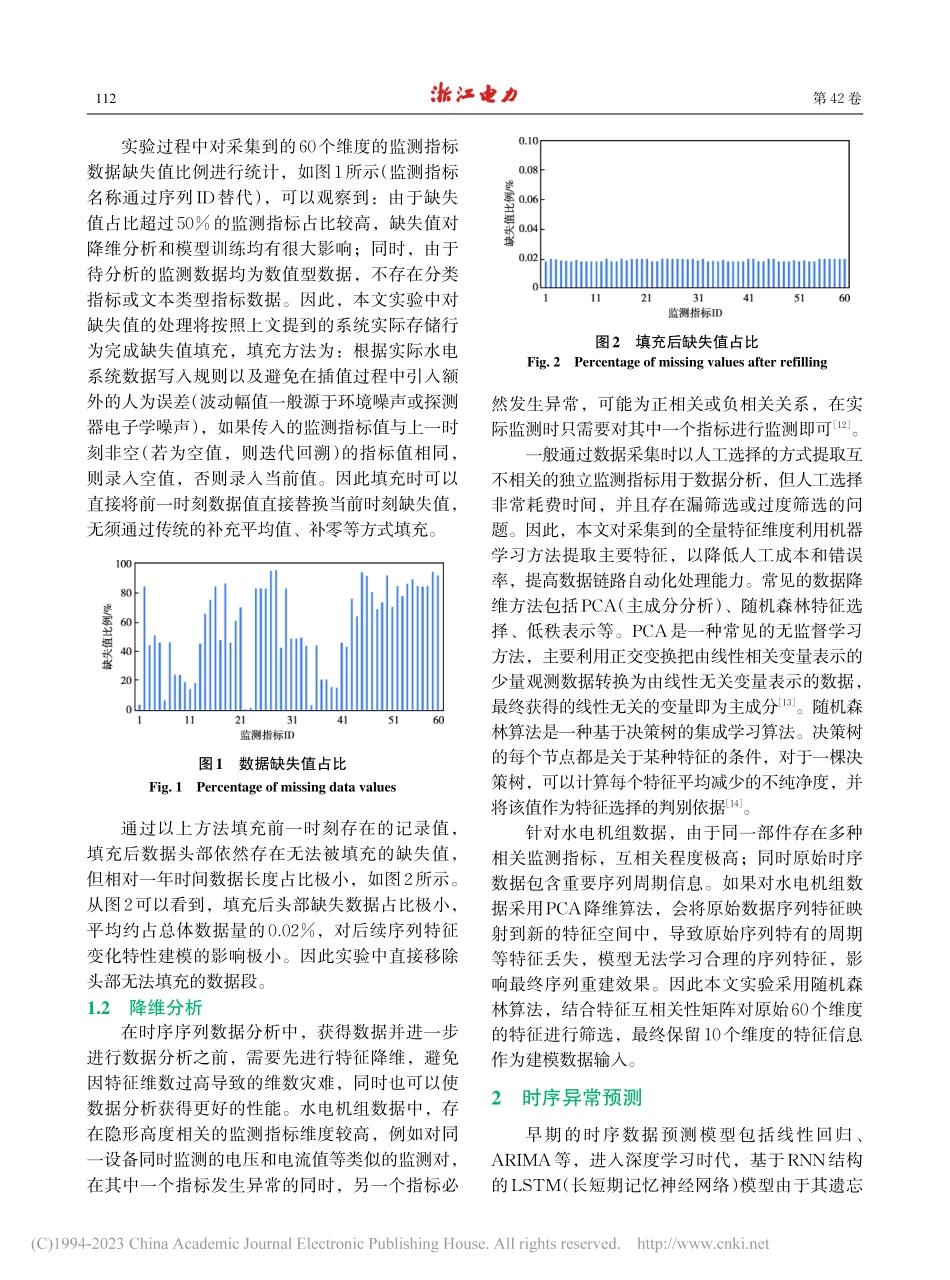
ZhejiangElectricPower第42卷第1期2023年1月Vol.42,No.01Jan.25.2023Transformer在水电机组异常指标预测的应用林烨敏1,王宁1,邱荣杰1,汤宇超1,周冠群2,李泽洲2,王中亚2(1.国网浙江省电力有限公司紧水滩水力发电厂,浙江丽水323000;2.宁波工业互联网研究院,浙江宁波315016)摘要:水电站机组日常检修、维护及异常检测的工作量巨大,传统人工监测的工作方式容易导致异常问题被遗漏或误判,采用深度学习算法对数据建模并监测异常情况可以降低成本,提升安全可靠性。结合Transformer网络对长期序列高效准确建模的能力以及GAN(生成对抗网络)架构的数据生成训练策略,利用TransGAN模型对水电机组监测数据进行生成式建模,并主动发现异常数据点。TransGAN模型在水电站机组实测中达到了97.76%的查准率和99.23%的查全率,异常点检出延迟低于0.1s,实现了实时高精度异常监控功能。关键词:水电机组;异常监测;数据降维;Transformer;生成对抗网络DOI:10.19585/j.zjdl.202301014开放科学(资源服务)标识码(OSID):ApplicationofTransformerinanomalyindicatorsforecastingofhydropowerunitsLINYemin1,WANGNing1,QIURongjie1,TANGYuchao1,ZHOUGuanqun2,LIZezhou2,WANGZhongya2(1.JinshuitanHydropowerPlantofStateGridZhejiangElectricPowerCo.,Ltd.,Lishui,Zhejiang323000,China;2.NingboIndustrialInternetInstitute,Ningbo,Zhejiang315016,China)Abstract:Theworkloadsofroutinerepair,maintenance,andabnormalitydetectionofhydropowerunitsareheavy.Therefore,traditionalmanualmonitoringmayleaveoutormisjudgeabnormalities.Deeplearningalgorithmsareusedfordatamodelingandmonitoringabnormalitiestoreducecostsandimprovesafetyandreliability.WiththehelpoftheTransformerneuralnetworks,theefficientandaccuratemodelingcapacityoflong-termsequencesandtheGAN(generativeadversarialnetwork)architecturedataareusedtogenerateatrainingstrategy.ATransGANmodelisusedforgenerativemodelingofthemeasureddataofhydropowerunitsandproactivelydetectsabnormaldatapoints.TheTransGANmodelachievesadetectionaccuracyrateof97.76%andarecallrateof99.23%inhydro⁃powerdatameasurement.Theanomalydetectiondelayislessthan0.1s.Thereal-timehigh-precisionanomalymoni⁃toringfunctionisrealized.Keywords:h...